BEiT-3: Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
언어, 비전, 그리고 멀티모달 사전학습의 큰 융합이 등장하고 있다. 본 논문에서는 비전 및 비전-언어 작업 모두에서 최고의 전이 성능을 달성하는 범용 멀티모달 기반 모델 BEiT-3를 소개한다. 구체적으로 백본 아키텍처, 사전학습 작업, 그리고 모델 스케일링 업의 세 가지 측면에서 큰 융합을 발전시킨다. 일반적인 목적의 모델링을 위한 멀티웨이 트랜스포머를 소개한다. 여기서 모듈식 아키텍처는 깊은 융합과 모달리티 특정 인코딩을 모두 가능하게 한다. 공유된 백본을 기반으로, 이미지(Imglish), 텍스트(English), 그리고 이미지-텍스트 쌍(“병렬 문장”)에 대해 통일된 방식으로 마스크된 “언어” 모델링을 수행한다. 실험 결과에 따르면 BEiT-3는 객체 탐지(COCO), 의미 분할(ADE20K), 이미지 분류(ImageNet), 시각적 추론(NLVR2), 시각적 질문 응답(VQAv2), 이미지 캡셔닝(COCO), 그리고 크로스-모달 검색(Flickr30K, COCO)에서 최고의 성능을 보여준다.
📋 Table of Contents
- 1 Introduction: The Big Convergence
- 2 BEiT-3: A General-Purpose Multimodal Foundation Model
- 3 Experiments on Vision and Vision-Language Tasks
- 4 Conclusion
1 Introduction: The Big Convergence
- 언어, 비전, 멀티모달 사전 학습 분야의 융합 추세를 보였다.
- 대규모 데이터를 활용한 사전 학습을 통해 모델을 다양한 다운스트림 태스크로 쉽게 적용할 수 있다.
- BEiT-3는 언어에서 비전 및 멀티모달 문제로의 변환, 네트워크 구조의 통합을 통해 다양한 모달리티를 원활하게 처리한다.
- 멀티웨이 트랜스포머(Multiway Transformers)는 다양한 다운스트림 태스크에 대해 하나의 통합된 구조를 제공한다.
- 마스크 데이터 모델링을 기반으로 하는 사전 학습 과제는 텍스트, 이미지, 이미지-텍스트 쌍 등 다양한 모달리티에 성공적으로 적용되었다.
- 이미지를 외국어(Imglish)로 간주하고 텍스트와 이미지를 동일한 방식으로 처리함으로써 모달리티 간 정렬을 학습한다.
- 모델 크기와 데이터 크기를 확장함으로써 기초 모델의 일반화 능력이 향상된다.
- BEiT-3는 마스크된 데이터 모델링을 통해 이미지, 텍스트, 이미지-텍스트 쌍을 사전 학습한다.
- 자기 지도 학습 목표는 손상된 입력을 바탕으로 원래의 토큰(텍스트 토큰 또는 시각적 토큰)을 복구하는 것이다.
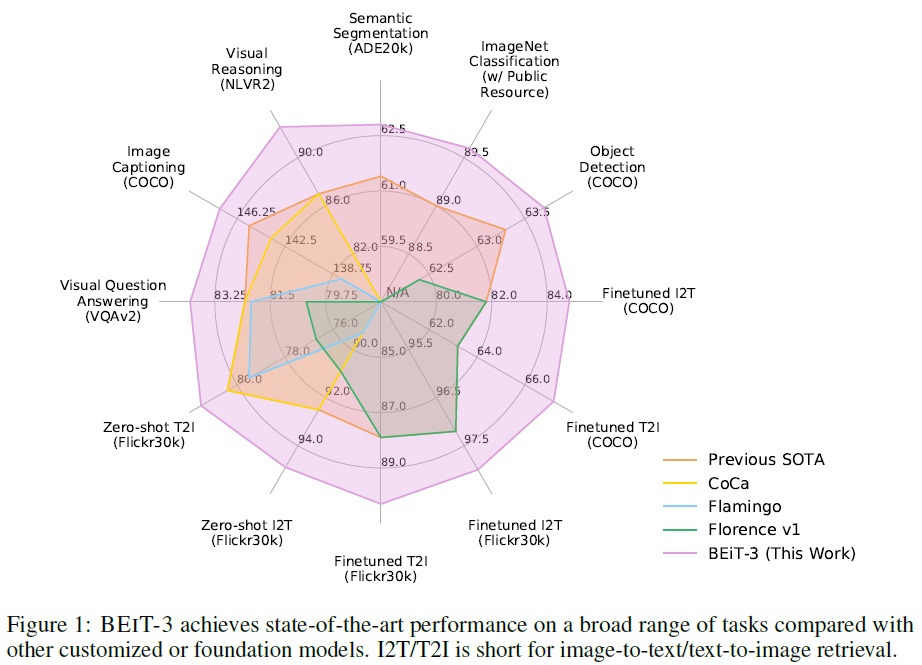
- BEiT-3는 다양한 비전 및 비전-언어 작업에 걸쳐 최고의 성능을 달성한다.
-
모델은 비전-언어 작업뿐만 아니라 비전 작업(객체 탐지, 의미 분할 등)에서도 잘 수행된다.
2 BEiT-3: A General-Purpose Multimodal Foundation Model
2.1 Backbone Network: Multiway Transformers
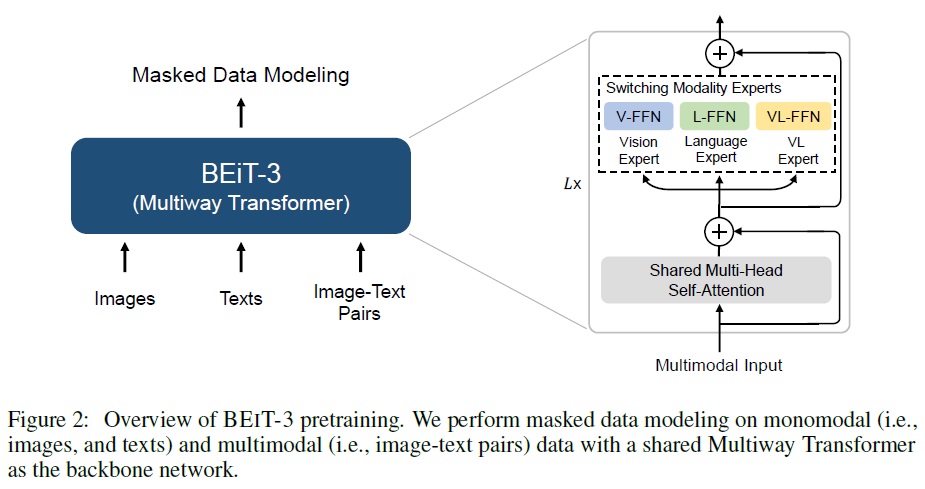
- 멀티웨이 트랜스포머를 다양한 모달리티를 인코딩하는 기반 모델로 사용한다.
- Fig 2와 같이 각 멀티웨이 트랜스포머 블록은 공유 셀프 어텐션 모듈과 다양한 모달리티를 위한 피드포워드 네트워크 풀(모달리티 전문가)로 구성된다.
- 각 입력 토큰을 해당 모달리티의 전문가에게 라우팅한다.
- 모달리티 전문가 풀을 사용하여 모달리티 특정 정보를 더 잘 포착한다.
-
공유 셀프 어텐션 모듈은 다양한 모달리티 간의 정렬을 학습하고 멀티모달 작업을 위한 깊은 퓨전을 가능하게 한다.
2.2 Pretraining Task: Masked Data Modeling
- 단일 및 멀티모달 데이터에 대한 통합된 마스크된 데이터 모델링 목표를 사용한다.
- 사전 학습 중 텍스트 토큰 또는 이미지 패치의 일부를 무작위로 마스크하고 마스크된 토큰을 복구하도록 모델을 학습한다.
- 텍스트 데이터는 SentencePiece 토크나이저로 토크나이징하고, 이미지 데이터는 BEiT v2의 토크나이저로 토크나이징하여 시각적 토큰을 재구성 목표로 사용한다.
- 마스크-then-예측 작업으로 훨씬 더 작은 사전 학습 배치 크기를 사용할 수 있다.
- 반면에 대조 기반 모델들은 일반적으로 사전 학습을 위해 매우 큰 배치 크기가 필요하며, 이는 GPU 메모리 비용과 같은 더 많은 엔지니어링 문제를 야기한다.
2.3 Scaling Up: BEiT-3 Pretraining
- Backbone Network
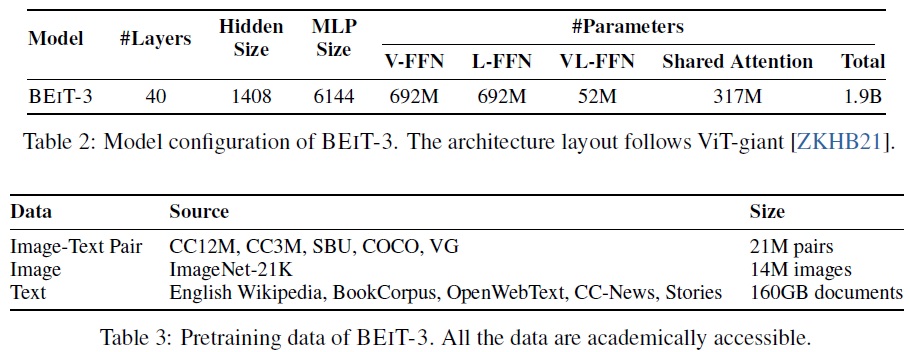
- BEiT-3는 ViT-giant 설정을 따르는 거대한 크기의 기반 모델이다.
- Table 2와 같이 1,408의 숨겨진 크기, 6,144의 중간 크기, 그리고 16개의 주의 헤드를 가진 40층의 멀티웨이 트랜스포머로 구성된다.
- 모든 레이어는 vision expert와 language expert를 포함한다.
- 상위 세 개의 멀티웨이 트랜스포머 레이어에는 Vision-language experts가 사용된다.
- self-attention module은 다양한 모달리티에 걸쳐 공유된다.
- BEiT-3는 총 1.9B 파라미터로 구성된다.(vision experts 692M, language experts 692M, vision-language experts 52M, self-attention module 317M)
- Pretraining Data
- Table 3과 같이 단일 모달 및 멀티모달 데이터로 사전 학습 된다.
- 멀티모달 데이터의 경우 약 15M개의 이미지와 21M개의 이미지-텍스트 쌍이 다섯 개의 공개 데이터셋에서 수집한다.
- 단일 모달 데이터의 경우 ImageNet-21K에서 14M개의 이미지와 영어 위키피디아, BookCorpus, OpenWebText3, CC-뉴스, 스토리에서 160GB의 텍스트 코퍼스를 사용한다.
- Pretraining Settings
- BEIT-3를 100만 스텝 동안 사전 학습했다.
- 각 배치는 총 6144개의 샘플을 포함하며, 이 중 2048개는 이미지, 2048개는 텍스트, 2048개는 이미지-텍스트 쌍이다.
- BEiT-3는 14 × 14 패치 크기를 사용하며 224 × 224 해상도에서 사전 학습된다.
- 작위 크기 조정된 크로핑, 수평 뒤집기 및 색상 지터링을 포함한 이미지 증강 전략을 활용한다.
- 64k 어휘 크기를 가진 SentencePiece 토크나이저를 사용하여 텍스트 데이터를 토큰화한다.
- AdamW 옵티마이저를 사용하여 최적화한다.
- 학습률은 1e-3의 피크, 10k 단계의 선형 워밍업, 코사인 학습률 감쇠 스케줄러를 사용한다.
- 트랜스포머 학습 안정화를 위해 BEiT 초기화 알고리즘을 활용하였다.
3 Experiments on Vision and Vision-Language Tasks
- BEIT-3를 비전-언어 및 비전 작업을 위한 주요 공개 벤치마크에서 광범위하게 평가한다.
3.1 Vision-Language Downstream Tasks
- 시각적 질문 답변, 시각적 추론, 이미지-텍스트 검색, 이미지 캡셔닝 벤치마크에서 BEiT-3의 능력을 평가한다.
- Visual Question Answering (VQA)
- 모델은 입력 이미지에 대한 자연어 질문에 답해야 한다.
- VQA v2.0 데이터셋에서 분류 문제로 과제를 설정하고 미세 조정 실험을 수행한다.
- BEiT-3는 이미지와 질문의 깊은 상호 작용을 모델링하기 위해 융합 인코더로 미세 조정된다.
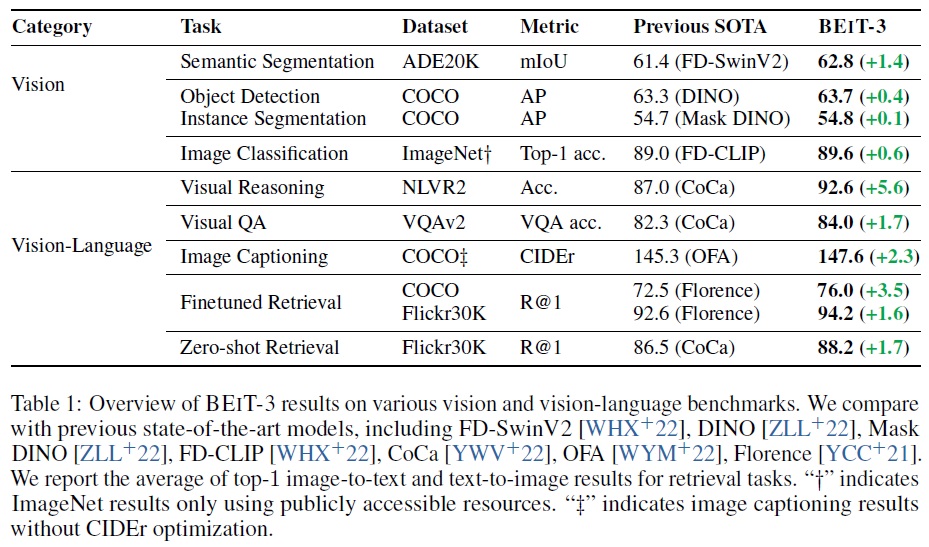
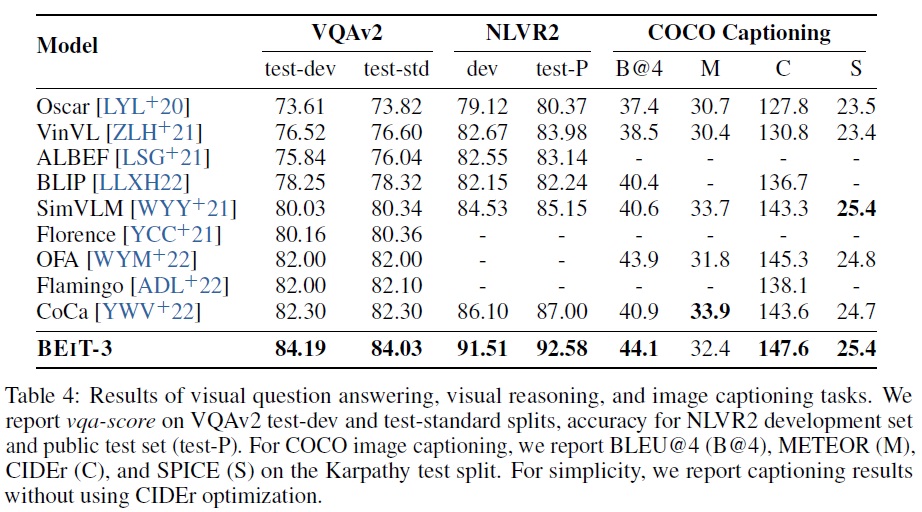
- Table 4에 따르면 단일 모델로 최첨단 성능을 84.03으로 밀어 올린다.
- Visual Reasoning
- 모델은 이미지와 자연어 설명에 대한 공동 추론을 수행해야 한다.
- NLVR2 벤치마크에서 모델을 평가한다.
- Table 4에 따르면 BEiT-3는 비전-언어 작업에서 SoTA 결과를 달성한다.
- Image Captioning
- 주어진 이미지에 대한 자연어 캡션을 생성하는 것이 목표다.
- COCO 벤치마크를 사용하여 모델을 미세 조정하고 평가한다.
- Table 4에 따르면 BEiT-3는 크로스 엔트로피 손실로 학습된 이전 모델들을 능가한다.
- Image-Text Retrieval
- 이미지와 텍스트 간의 유사성을 측정하는 작업이다.
- COCO와 Flickr30K 벤치마크를 사용하여 모델을 평가한다.
- BEiT-3는 이미지-텍스트 검색을 위해 듀얼 인코더로 미세 조정된다.
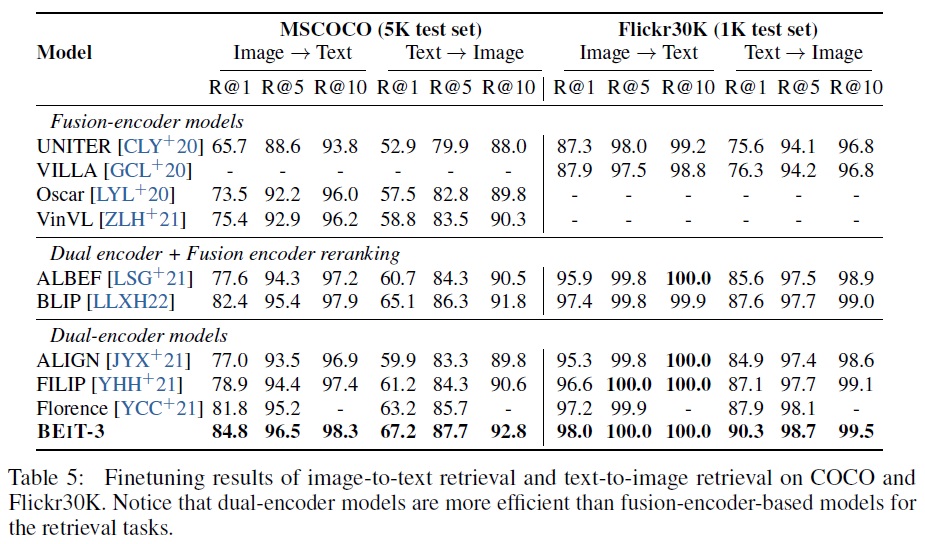
- Table 5에 제시된 미세 조정 결과에 따르면, 듀얼 인코더 BEiT-3는 이전 모델들을 큰 차이로 능가한다.
- BEiT-3는 또한 추론을 위한 더 많은 계산 비용이 필요한 융합 인코더 기반 모델들을 크게 능가
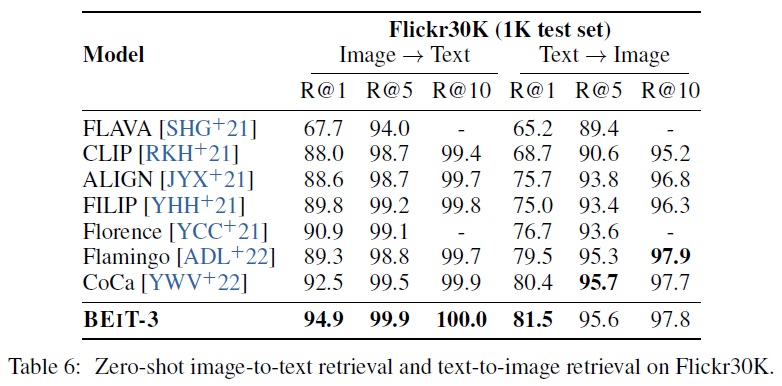
- Table 6에 따르면 BEiT-3는 COCO와 Flickr30K 제로샷 검색에서도 이전 모델들을 큰 차이로 능가한다.
3.2 Vision Downstream Tasks
- BEiT-3은 비전-언어 작업뿐만 아니라 객체 탐지, 인스턴스 분할, 의미론적 분할, 이미지 분류를 포함한 다양한 비전 다운스트림 작업으로 전환된다.
- 비전 인코더로 사용될 때, BEiT-3의 유효 파라미터 수는 ViT-giant와 비슷하며, 약 10억에 해당한다.
- Object Detection and Instance Segmentation
- COCO 2017 벤치마크에서 미세 조정 실험을 수행한다. 이 데이터셋은 118k 학습 이미지, 5k 검증 이미지, 20k 테스트-개발 이미지를 포함한다.
- 객체 탐지 및 인스턴스 분할 작업을 위해 ViTDet을 따르고, 간단한 feature pyramid와 window attention를 포함한 BEiT-3를 백본으로 사용한다.
- 우선 Objects365 데이터셋에서 중간 미세 조정을 수행한 후 COCO 데이터셋에서 모델을 미세 조정한다.
- 추론 중에 Soft-NMS를 사용한다.
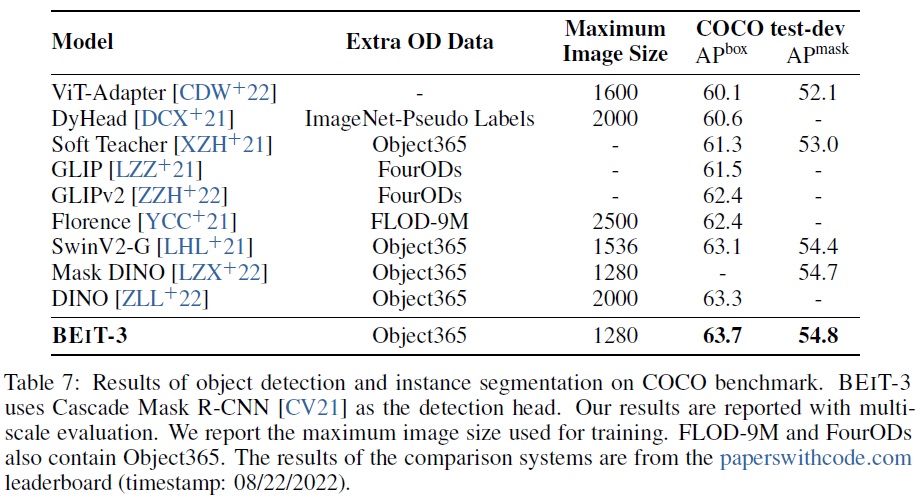
- Table 7에 따르면 BEiT-3는 COCO 객체 탐지 및 인스턴스 분할에서 이전 최신 모델들을 능가하는 최고의 결과를 달성한다.
- 미세 조정에 사용된 이미지 크기가 더 작음에도 불구하고 63.7 박스 AP와 54.8 마스크 AP에 이른다.
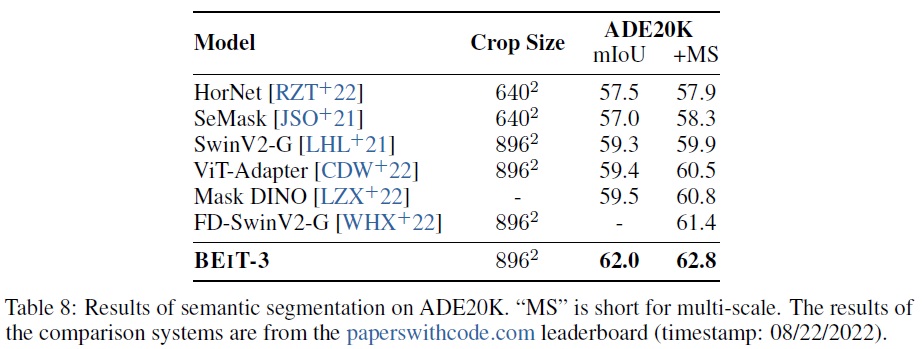
- Semantic Segmentation
- 의미론적 분할의 목표는 주어진 이미지의 각 픽셀에 대한 라벨을 예측하는 것이다.
- BEiT-3는 150개의 의미론적 범주를 포함하는 도전적인 ADE20K 데이터셋에서 평가된다.
- ADE20K는 20k 학습 이미지와 2k 검증 이미지를 포함한다.
- ViT-Adapter의 작업 전환 설정을 직접 따르며, 밀도 높은 예측 작업 어댑터를 사용하고 Mask2Former를 분할 프레임워크로 활용한다.
- Table 8에 따르면 BEiT-3는 62.8 mIoU로 새로운 SoTA 결과를 보이며, 3B 파라미터를 가진 FD-SwinV2 거대 모델을 1.4점 차이로 능가한다.
- Image Classification
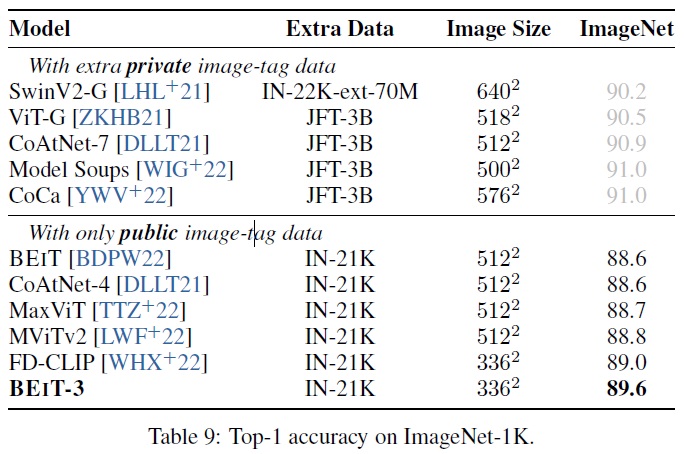
- 모델은 1.28M 학습 이미지와 50k 검증 이미지를 포함하는 1k 클래스의 ImageNet-1K에서 평가된다.
- 비전 인코더에 작업 레이어를 추가하는 대신 이미지-텍스트 검색 작업으로 작업을 설정한다.
- 카테고리 이름을 텍스트로 사용하여 이미지-텍스트 쌍을 구성한다.
- BEiT-3는 이미지에 가장 관련 있는 레이블을 찾기 위해 듀얼 인코더로 학습된다.
- 추론 중에는 가능한 클래스 이름의 피처 임베딩과 이미지의 피처 임베딩을 먼저 계산한다.
- 그 후 이들의 코사인 유사도 점수를 계산하여 각 이미지에 대한 가장 가능성 높은 레이블을 예측한다.
- Table 9에 따르면 BEiT-3는 공개 이미지-태그 데이터만을 사용할 때 이전 모델들을 능가하는 새로운 SoTA 결과를 만든다.
4 Conclusion
- BEiT-3는 범용 멀티모달 기반 모델로, 비전 및 비전-언어 벤치마크에서 SoTA를 달성한다.
- 이미지를 외국어로 모델링하여 이미지, 텍스트, 이미지-텍스트 쌍에 대한 마스크된 “언어” 모델링을 통합적으로 수행한다.
- 멀티웨이 트랜스포머는 다양한 비전 및 비전-언어 작업을 효과적으로 모델링할 수 있어, 범용 모델링을 위한 흥미로운 옵션이다.
- BEiT-3는 간단하면서도 효과적이며, 멀티모달 기반 모델을 확장하는 유망한 방향이다.
- 향후, 다양한 언어를 지원하는 멀티모달 BEiT-3를 사전 학습하고, 더 많은 모달리티(예: 오디오)를 포함하여 언어 간 및 모달리티 간 전이를 용이하게 하고, 작업, 언어, 모달리티에 걸친 대규모 사전 학습의 큰 융합을 촉진할 계획이다.
- BEiT-3와 MetaLM의 강점을 결합하여 멀티모달 기반 모델의 in-context learning 능력을 가능하게 할 예정이다.
댓글남기기