What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis
최근 몇 년 동안 Scene Text Recognition(STR) 모델에 대한 많은 새로운 제안이 도입되었다. 기존 연구들은 기술의 경계를 넓혔다고 주장하지만, 학습 및 평가 데이터셋의 일관성 없는 선택으로 인해 전체적이고 공정한 비교가 대부분 누락되었다. 본 논문은 세 가지 주요 기여를 통해 이 어려움을 해결한다. 첫째, 학습 및 평가 데이터셋의 불일치와 불일치로 인한 성능 격차를 검토한다. 둘째, 대부분의 기존 STR 모델에 맞춰질 수 있는 통합된 네 단계 STR 프레임워크를 소개한다. 이 프레임워크를 사용하면 이전에 제안된 STR 모듈의 광범위한 평가와 이전에 탐색되지 않은 모듈 조합의 발견이 가능하다. 셋째, 하나의 일관된 학습 및 평가 데이터셋 세트에서 정확도, 속도 및 메모리 요구 사항 측면에서 모듈별 기여도를 분석한다. 이러한 분석은 현재의 비교에서 이해하기 어려운 기존 모듈의 성능 향상에 대한 장애를 해결한다. 본 논문의 코드는 이 링크에서 공개적으로 이용 가능하다.
📋 Table of Contents
- 1. Introduction
- 2. Dataset Matters in STR
- 3. STR Framework Analysis
- 4. Experiment and Analysis
- 5. Conclusion
1. Introduction
- 자연 장면에서 텍스트를 읽는 장면 텍스트 인식(Scene Text Recognition, STR)은 다양한 산업 응용 분야에서 중요한 작업이다.
- 기존 광학 문자 인식(Optical Character Recognition, OCR) 방법들은 실제 세계의 다양한 텍스트 외형과 장면이 캡처된 불완전한 조건들로 인해 STR 작업에서 그만큼 효과적이지 못하다.
- 이전 연구들은 특정 도전을 해결하는 깊은 신경망으로 이루어진 다단계 파이프라인을 제안했다.
- 예를 들어, Shi et al.은 입력된 문자 수의 변화를 처리하기 위해 순환 신경망을, 문자 수를 식별하기 위해 연결주의 시간 분류 손실을 제안했다.
- 새롭게 제안된 모듈이 기존의 방법을 어떻게 개선하는지 평가하기 어렵다. 이는 다른 평가 및 테스트 환경이 상이하기 때문이다.
- 학습 데이터셋과 평가 데이터셋 사용에 일관성이 없어 다른 모델들 사이의 성능 비교가 공정하지 않았다.
- 본 논문은 STR 데이터셋을 분석하여 데이터셋 사용의 일관성 없음과 그 원인을 분석한다.
- STR을 위한 통합 프레임워크를 소개하여 기존 방법에 대한 공통적인 관점을 제공한다.
- 모델을 변환(Trans.), 특징 추출(Feat.), 시퀀스 모델링(Seq.), 예측(Pred.)의 네 가지 연속적인 작업 단계로 나눈다.
- 통합 실험 설정 아래에서 정확도, 속도, 및 메모리 요구 사항 측면에서 모듈별 기여를 연구한다.
- 개별 모듈의 기여를 더 엄격하게 평가하고, 기존 모델보다 개선된 모듈 조합을 제안한다.
- 벤치마크 데이터셋에서의 실패 사례를 분석하여 STR의 남은 도전 과제를 식별한다.
2. Dataset Matters in STR
- 이전 작업에서 사용된 다양한 학습 및 평가 데이터셋 검토하고 차이점을 다룬다.
- 각 연구가 데이터셋을 구성하고 사용하는 방식에서 어떻게 다른지 강조한다.
- 다른 작업 간 성능 비교 시 일관성 없음으로 인한 편향 조사한다.
- 데이터셋의 불일치로 인한 성능 격차 측정 및 논의한다.
2.1. Synthetic datasets for training
- STR 모델 학습 시, 현장 텍스트 이미지의 레이블링 비용이 많이 소요되고 충분한 레이블링 데이터를 얻기 어렵기 때문에, 대부분의 STR 모델은 학습을 위해 합성 데이터셋을 사용한다.
- Fig 1과 같이 가장 인기 있는 두 가지 합성 데이터셋 소개: MJSynth (MJ), SynthText (ST)
- MJSynth (MJ)
- STR을 위해 설계된 합성 데이터셋이다.
- 총 8.9M 단어 상자 이미지 포함한다.
- 생성 과정에는 폰트 렌더링, 테두리 및 그림자 렌더링, 배경 색칠, 폰트/테두리/배경의 합성, 투영 왜곡 적용, 실제 세계 이미지와의 혼합, 노이즈 추가가 포함된다.
- SynthText (ST)
- 또 다른 합성으로 생성된 데이터셋으로, 원래는 장면 텍스트 검출을 위해 설계된다.
- 장면이미지에 단어를 렌더링하는 예시를 포함된다.
- 비록 SynthText가 장면 텍스트 검출 작업을 위해 설계되었지만, 단어 박스를 잘라내어 STR에도 사용된다.
- 비영숫자 문자를 제외하고 단어 박스를 잘라내고 필터링하면 5.5M의 학습 데이터가 있다.
- 이전 작업들은 MJ, ST, 또는 다른 출처들의 다양한 조합을 사용한다.
- 데이터셋 사용의 일관성 부족이 성능 개선이 모듈의 기여 때문인지, 아니면 더 나은 또는 더 큰 학습 데이터 때문인지 의문을 제기한다.
- 학습 데이터셋이 벤치마크에서의 최종 성능에 미치는 영향에 대해 실험적으로 설명한다.
- 향후 STR 연구에서는 사용된 학습 데이터셋을 명확히 밝히고 동일한 학습 세트를 사용하여 모델을 비교할 것을 제안한다.

2.2. Real-world datasets for evaluation
- STR 모델 평가에 널리 사용되는 일곱 가지 실제 데이터셋이 있다.
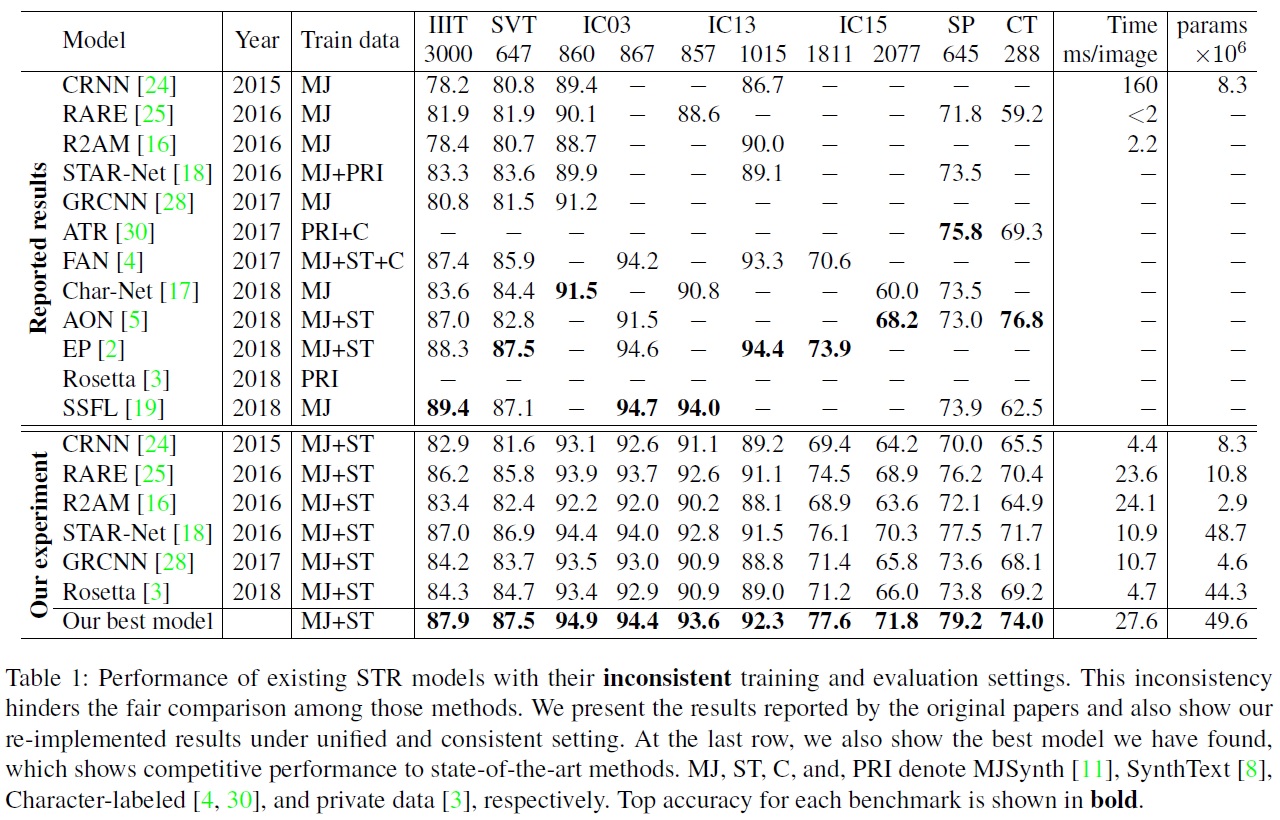
- Table 1과 같이 일부 벤치마크 데이터셋의 경우 이전 작업마다 평가를 위해 데이터셋의 다른 하위 집합(different subsets)이 사용되었으며, 이는 일관성 없는 비교를 초래한다.
- Fig2와 같이 데이터셋을 “정규”와 “비정규”로 분류한다.
- 정규 데이터셋(regular datasets): 문자가 수평으로 배치되고 서로 사이에 균일한 간격이 있는 텍스트 이미지를 포함한다.
- IIIT5K-Words (IIIT): Google 이미지 검색에서 크롤링한 데이터셋으로 2,000개 학습 이미지와 3,000개 평가 이미지를 포함한다.
- Street View Text (SVT): Google Street View에서 수집된 야외 거리 이미지로 257개 학습 이미지와 647개 평가 이미지를 포함한다.
- ICDAR2003 (IC03): 카메라로 촬영된 장면 텍스트를 읽기 위한 ICDAR 2003 Robust Reading 경쟁을 위해 생성되었다. 1,156개의 학습 이미지와 1,110개의 평가 이미지를 포함한다.(비알파벳 문자 또는 3자 미만 단어 제외 시 867개)
- ICDAR2013 (IC13): IC03의 대부분 이미지를 상속받고 ICDAR 2013 Robust Reading 경쟁을 위해 생성되었다. 848개의 학습 이미지와 1,095개의 평가 이미지를 포함한다. (비알파벳 문자를 포함한 단어 제외 시 1,015개)
- 비정규 데이터셋(irregular datasets): 곡선이 있는 텍스트, 임의로 회전되거나 왜곡된 텍스트와 같은 STR의 어려운 코너 케이스를 일반적으로 포함한다.
- ICDAR2015 (IC15): ICDAR 2015 Robust Reading 경쟁을 위해 생성되었다. Google Glass를 통해 캡처된 4,468개의 학습 이미지와 2,077개의 평가 이미지를 포함한다. 많은 이미지가 노이즈가 많고, 흐리며, 회전되었고, 일부는 해상도가 낮다. 평가를 위한 또 다른 버전은 1,811개와 2,077개 이미지를 포함하고 있으며,비알파벳 문자 이미지와 일부 극도로 회전되고 관점이 변경되며 곡선이 있는 이미지를 제외하고 1,811개의 이미지만 사용했다.
- SVT Perspective (SP): Google Street View에서 수집된 645개의 평가 이미지를 포함한다. 많은 이미지가 비정면 시점으로 인한 관점 투영을 포함한다.
- CUTE80 (CT): 자연 장면에서 수집된 288개의 잘린 이미지를 포함한다. 많은 이미지가 곡선 텍스트 이미지를 포함한다.
- Table 1은 이전 작업들이 다른 벤치마크 데이터셋에서 모델을 평가했다는 중요한 문제를 강조한다.
- IC03, IC13, IC15의 다른 버전에서 평가가 이루어졌으며, IC03에서는 7개의 예시가 이전 성능들과 비교할 때 0.8%라는 큰 성능 격차를 일으킬 수 있다.
- IC13과 IC15에서는 예시 번호의 격차가 IC03보다 더 크다.

3. STR Framework Analysis
- 독립적으로 제안된 STR 모델들 사이의 공통점에서 유래된 네 단계로 구성된 장면 텍스트 인식(STR) 프레임워크를 소개한다.
- 컴퓨터 비전 작업(예: 객체 탐지) 및 시퀀스 예측 작업과의 유사성으로 인해, STR은 고성능 컨볼루셔널 신경망(CNN)과 순환 신경망(RNN)의 혜택을 받는다.
- CNN과 RNN을 결합한 첫 번째 STR 응용인 Convolutional-Recurrent Neural Network (CRNN)는 입력 텍스트 이미지에서 CNN 특징을 추출하고, 이를 RNN으로 재구성하여 강력한 시퀀스 예측을 달성한다.
- Fig 3과 같이 STR 프레임워크 네 단계로 분류한다.
- Transformation (Trans.): 입력 텍스트 이미지를 Spatial Transformer Network(STN)를 사용하여 정규화하여 후속 단계를 용이하게 한다.
- Feature extraction (Feat.): 입력 이미지를 문자 인식에 관련된 속성에 초점을 맞춘 표현으로 매핑하면서 글꼴, 색상, 크기, 배경 등 관련 없는 특징을 억제한다.
- Sequence modeling (Seq.): 문자의 시퀀스 내에서 맥락 정보를 포착하여 다음 단계에서 각 문자를 더 견고하게 예측할 수 있게 한다.
- Prediction (Pred.): 이미지의 식별된 특징으로부터 출력 문자 시퀀스를 추정한다.

3.1. Transformation stage
- 이 단계의 모듈은 입력 이미지 X를 정규화된 이미지 $\tilde{X}$ 로 변환한다.
- 자연 장면에서의 텍스트 이미지는 다양한 형태를 띠며, 곡선이 있거나 기울어진 텍스트를 포함할 수 있다.
- 입력 이미지가 변경 없이 제공되면, 후속 특징 추출 단계는 이러한 기하학적 변형에 대해 불변하는 표현을 학습해야 한다.
- 이러한 부담을 줄이기 위해 Thin-Plate Spline(TPS)변환을 적용해야 한다. TPS는 공간 변환 네트워크(STN)의 변형으로, 텍스트 라인의 다양한 종횡비에 유연하게 적용될 수 있다.
- TPS는 일련의 기준점 사이에서 부드러운 스플라인 보간(smooth spline interpolation)을 사용하며, 상단과 하단을 둘러싼 점들에서 다수의 기준점(Fig 3에서 녹색 ‘+’ 표시)을 찾아 문자 영역을 미리 정의된 직사각형으로 정규화한다.
- 프레임워크는 TPS의 선택 또는 선택 해제를 허용한다.
3.2. Feature extraction stage
- 특징 추출 단계의 목적은 CNN을 사용하여 입력 이미지 $\mathbf{X}$ 또는 $\tilde{\mathbf{X}}$를 추상화하고 시각적 특징 맵 $\mathbf{V} = {v_i}; i = 1, \ldots, I$를 출력하는 것이다. (여기서 $I$는 특징 맵의 열 수이다.)
- 결과적인 특징 맵의 각 열은 입력 이미지의 수평선을 따른 구분 가능한 수용 필드에 해당하며, 이 특징들은 각 수용 필드에서 문자를 추정하는 데 사용된다.
- 특징 추출 단계에서 연구된 세 가지 아키텍처는 다음과 같습니다
- VGG: 여러 개의 컨볼루셔널 레이어를 거친 후 몇 개의 완전 연결 레이어로 구성된다.
- RCNN: 문자 형태에 따라 수용 필드를 조정할 수 있도록 재귀적으로 적용될 수 있는 CNN의 변형이다.
- ResNet: 상대적으로 더 깊은 CNN의 학습을 용이하게 하는 잔여 연결을 가진 CNN입니다.
- 이 단계에서의 아키텍처 선택은 STR 시스템의 전체 성능에 중요한 영향을 미치며, 다양한 형태의 텍스트 이미지에 대한 효과적인 특징 추출을 가능하게 한다.
3.3. Sequence modeling stage
- 특징 추출 단계에서 추출된 특징들을 시퀀스 형태의 특징 $V$로 재구성한다. 즉, 특징 맵의 각 열 $v_i \in V$는 시퀀스의 프레임으로 사용된다.
- 이 시퀀스는 문맥 정보의 부족으로 인해 문제를 겪을 수 있다.
- 일부 이전 작업들은 더 나은 시퀀스 $H=Seq(V)$를 만들기 위해 양방향 LSTM(BiLSTM)을 사용한다.
- Rosetta와 같은 일부 방법은 계산 복잡성과 메모리 소비를 줄이기 위해 BiLSTM을 제거했다.
- 본 논문의 프레임워크는 BiLSTM의 선택 또는 선택 해제를 허용한다.
- 이 단계는 성능과 계산 복잡성 사이에서 균형을 맞출 수 있는 옵션을 갖는다.
3.4. Prediction stage
- 입력 $H$로부터 문자 시퀀스 (예: $Y=y_1,y_2,…$)를 예측하는 두 가지 모듈을 사용한다.
- Connectionist temporal classification (CTC)
- 고정된 수의 특징이 주어지더라도 고정되지 않은 수의 시퀀스를 예측할 수 있게 한다.
- 주요 방법은 각 열 ($ℎ_i \in H$)에서 문자를 예측하고, 반복되는 문자와 공백을 삭제함으로써 전체 문자 시퀀스를 고정되지 않은 문자 스트림으로 수정하는 방법을 사용한다.
- attention-based sequence prediction (Attn)
- 입력 시퀀스 내의 정보 흐름을 자동으로 포착하여 출력 시퀀스를 예측한다.
- STR 모델이 출력 클래스 의존성을 나타내는 문자 수준 언어 모델을 학습할 수 있게 한다.
- CTC와 Attn 중에서 선택할 수 있다.
- CTC는 고정되지 않은 길이의 출력을 다루는 데 유용하며, Attn은 문자 간 의존성을 더 잘 학습할 수 있는 장점을 가진다.
4. Experiment and Analysis
4.1. Implementation detail
- 학습, 검증, 평가 데이터셋의 선택은 STR 모델의 성능 측정에 큰 영향을 미친다.
- 공정한 비교를 위해 학습, 검증, 평가 데이터셋의 선택을 고정해야 한다.
- STR training and model selection
- 학습 데이터셋은 MJSynth 8.9M과 SynthText 5.5M으로 총 14.4M 사용한다.
- 옵티마이저는 AdaDelta를 사용하며, decay rate는 0.95로 설정한다.
- 학습 배치 크기는 192이며, 반복 횟수는 300K이다.
- 그래디언트 클리핑의 크기는 5에서 사용된다.
- 모든 파라미터 He의 방법으로 초기화한다.
- 검증 데이터로 IC13, IC15, IIIT, SVT의 학습 세트의 합집합을 사용한다.
- 모델을 2,000 학습 스텝마다 검증하여 가장 높은 정확도 모델을 선택한다.
- IC03 데이터는 평가 데이터셋과의 중복을 피하기 위해 제외한다.
- Evaluation metrics
- 정확도, 시간, 메모리 측면에서 STR 조합에 대한 철저한 분석을 제공한다.
- 정확도는 이미지 당 단어 예측의 성공률을 9개 실제 세계 평가 데이터셋(총 8,539 이미지)에서 측정한다.
- 속도 평가는 동일한 컴퓨팅 환경에서 주어진 텍스트를 인식하는 데 걸리는 평균 클럭 시간(밀리초 단위)을 측정한다.
- 메모리 평가는 전체 STR 파이프라인에서 학습 가능한 부동 소수점 파라미터의 수를 계산한다.
- Environment
- Intel Xeon(R) E5-2630 v4 2.20GHz CPU, NVIDIA TESLA P40 GPU, 252GB RAM 환경에서 수행한다.
- 모든 실험은 NAVER Smart Machine Learning (NSML) 플랫폼에서 수행된다.
4.2. Analysis on training datasets
- 다양한 그룹의 학습 데이터셋 사용이 벤치마크에서의 성능에 얼마나 큰 영향을 미치는지 조사한다.
- 오직 MJSynth만 사용했을 때 총 정확도 80.0% 달성한다.
- 오직 SynthText만 사용했을 때 75.6% 달성한다.
- MJSynth와 SynthText를 함께 사용했을 때 84.1% 달성한다.
- MJSynth와 SynthText의 결합은 각각을 개별적으로 사용했을 때보다 정확도를 4.1% 이상 향상시킨다.
- MJSynth의 20% (1.8M)와 SynthText의 20% (1.1M)를 함께 학습시킬 때 총 2.9M (SynthText의 절반)을 사용하여 81.3%의 정확도를 달성한다. 이는 MJSynth나 SynthText를 개별적으로 사용했을 때보다 더 나은 성능을 보인다.
- MJSynth와 SynthText는 왜곡과 흐림과 같은 다른 옵션을 사용하여 생성되었기 때문에 서로 다른 특성을 가진다.
- 이 결과는 학습 데이터의 다양성이 학습 예제의 수보다 더 중요할 수 있으며, 다른 학습 데이터셋을 사용하는 것의 효과가 단순히 ‘더 많은 것이 더 좋다’고 결론짓기보다 더 복잡하다는 것을 보여준다.
4.3. Analysis of trade-offs for module combinations
- 다양한 모듈 조합에서 나타나는 정확도-속도 및 정확도-메모리 트레이드오프에 초점을 맞춘다.
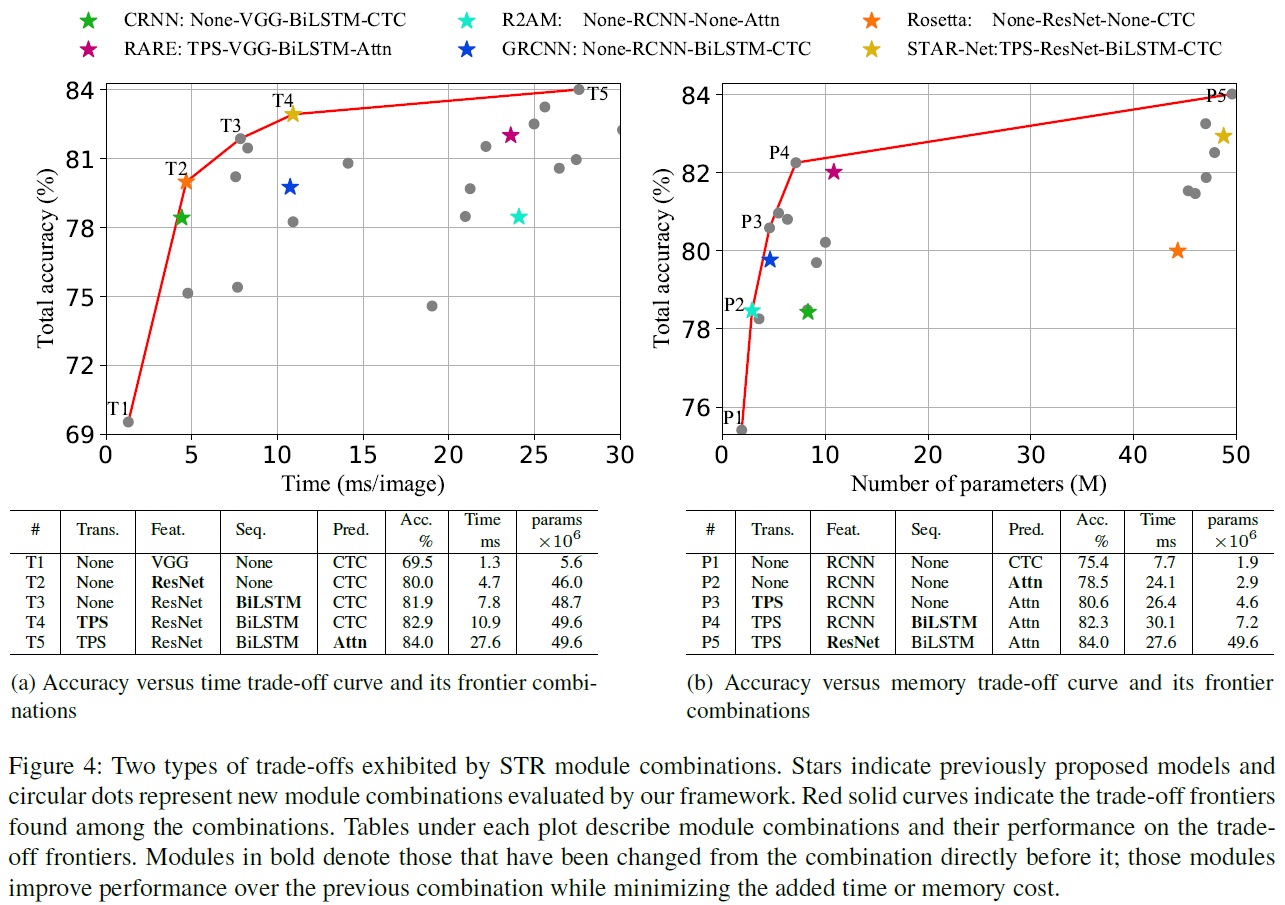
- Fig 4와 같이 총 24가지 조합의 트레이드오프 플롯을 제공한다.
- Analysis of combinations along the trade-off frontiers.
- accuracy-time trade-off (Fig 4(a))
- Rosetta와 STAR-net이 프론티어(최적선)에 위치한다.
- T1부터 T5까지의 모듈 조합은 순차적으로 ResNet, BiLSTM, TPS, Attn. 모듈을 도입함으로써 정확도를 향상시킨다.
- T1은 변환 또는 순차 모듈을 포함하지 않아 최소 시간을 소요한다.
- T5까지 각 단계마다 단일 모듈이 변경되어, 계산 효율성의 비용으로 성능이 향상된다.
- ResNet, BiLSTM, TPS는 비교적 적당한 전체 속도 저하로 정확도를 크게 향상시킨다.
- Attn 모듈의 추가는 효율성의 큰 비용으로 정확도를 단 1.1%만 향상시킨다.
- accuracy-memory trade-off (Fig 4(b))
- R2AM이 프론티어(최적선)에 위치한다.
- P1부터 P5까지의 모듈 조합은 메모리와 정확도 사이의 트레이드오프를 보여준다.
- P1은 메모리 소비가 가장 적은 모델이다.
- P1에서 P5로 가면서 변경된 모듈은 Attn, TPS, BiLSTM, ResNet이다.
- RCNN은 VGG와 비교하여 더 가볍고 좋은 정확도-메모리 트레이드오프를 제공한다.
- 변환, 순차, 예측 모듈은 메모리 소비에 크게 기여하지 않으며, 정확도 향상을 제공한다.
- ResNet의 추가는 메모리 소비를 크게 증가시키면서 정확도를 약간 향상시킨다.
- accuracy-time trade-off (Fig 4(a))
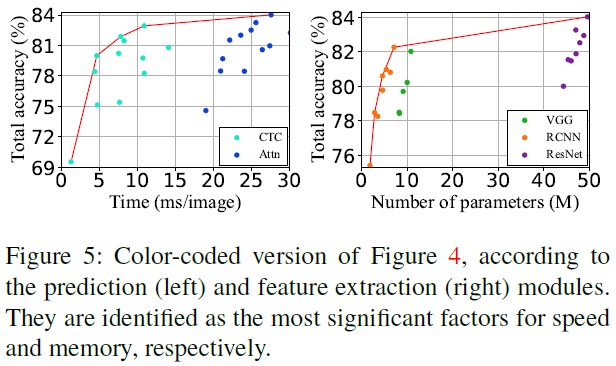
- The most important modules for speed and memory.
- 속도와 메모리에 가장 중요한 모듈, 즉 각각 예측 및 특징 추출 모듈을 각각 나타내는 산점도를 Fig 5에서 보여준다.
- 속도에는 예측 모듈이 메모리에는 특징 추출 모듈이 가장 큰 영향을 미친다.
- 속도에 대해 Attn 모듈의 추가가 전체 STR 모델을 상당히 느리게 한다.
- 메모리에 대해 특징 추출기가 가장 중요한 기여를 한다.
4.4. Module analysis
- Table 2에 포함된 모듈 조합을 평균내어 각 모듈의 성능을 평가한다.
- 각 단계에서 모듈을 업그레이드하면 추가적인 자원, 시간, 또는 메모리가 필요하지만, 이는 성능 향상을 제공한다.
- 비정규 데이터셋에서의 성능 향상이 정규 벤치마크의 약 두 배이다.
- 사용 측면에서 ResNet, BiLSTM, TPS, Attn 순서가 기본 조합(None-VGG-None-CTC)에서 모듈을 업그레이드하는 가장 효율적인 순서이다. 이 순서는 정확도-시간 프론티어(T1→T5)의 조합 순서와 동일이다.
- 정확도-메모리 관점에서는 RCNN, Attn, TPS, BiLSTM, ResNet 순서가 모듈을 업그레이드하는 가장 효율적인 순서이다. 이 순서는 정확도-메모리 프론티어(P1→P5)의 조합 순서와 같다.
- 시간 대 메모리에서의 모듈 순서 차이: 시간에 대한 모듈의 효율적 순서는 메모리에 대한 순서와 반대입니다.
- Qualitative analysis
- Fig 7은 특정 모듈이 업그레이드될 때(예: VGG에서 ResNet 백본으로)만 올바르게 인식되는 샘플을 보여준다.
- 업그레이드를 통해 인식이 가능해진 개선 사항을 보여준다.
- TPS 변환은 곡선 및 관점 텍스트를 표준화된 뷰로 정규화하여 텍스트 인식을 개선한다.
- ResNet은 밀집한 배경 잡음과 보지 못한 폰트에서 더 나은 표현력을 제공한다.
- BiLSTM은 더 나은 맥락 모델링을 통해 관련 없이 자른 문자를 무시할 수 있다.
- Attn (주의 메커니즘)은 누락되거나 가려진 문자를 찾아내어 텍스트 인식을 향상시킨다.

4.5. Failure case analysis
- 8,539개의 벤치마크 데이터셋 예시 중 644개 이미지(7.5%)가 24개 모델 중 어느 것으로도 올바르게 인식되지 않는 6가지 실패 사례를 Fig 6에 보여준다.
- Calligraphic fonts: 브랜드 또는 상점 이름에 사용된 독특한 폰트 스타일은 일반화된 시각적 특징을 제공하는 새로운 특징 추출기 개발이나 규제화를 통한 접근이 필요하다.
- Vertical texts: 현재의 STR 모델들은 주로 수평 텍스트 이미지를 처리하도록 설계되어 있어, 세로 텍스트를 효과적으로 처리할 수 없다.
- Special characters: 현재 벤치마크는 특수 문자를 평가하지 않으므로, 특수 문자를 학습에서 제외하게 되어 이를 영숫자 문자로 잘못 인식하게 된다. 특수 문자를 포함한 학습이 정확도를 향상시킬 수 있다.
- Heavy occlusions: 현재 방법들은 문맥 정보를 충분히 활용하지 못해 객체가 가려진 경우를 효과적으로 처리하지 못한다.
- Low resolution: 저해상도 이미지를 효과적으로 처리하기 위한 명시적인 방법이 부족하다. 이미지 피라미드나 초해상도 모듈이 해결책이 될 수 있다.
- Label noise: 실패 예제 중 일부는 부정확한 레이블링 때문이었다. 특수 문자를 고려하지 않을 때의 오류 라벨링 비율은 1.3%, 특수 문자를 고려할 때는 6.1%, 대소문자를 고려할 때는 24.1%였다.

5. Conclusion
- 새로운 장면 텍스트 인식(STR) 모델들이 크게 발전했음에도 불구하고, 일관성 없는 벤치마크로 인해 제안된 모듈이 STR 기본 모델을 어떻게 개선하는지 판단하기 어려웠다.
- 이전에 일관되지 않은 실험 설정으로 인해 가려졌던 기존 STR 모델의 기여를 분석한다.
- 주요 STR 방법론들 간의 공통 프레임워크 및 7 개의 벤치마크 평가 데이터셋과 2 개의 학습 데이터셋(MJ와 ST) 도입한다.
- 주요 STR 방법론들 간의 공정한 비교를 제공하며, 어떤 모듈이 가장 큰 정확도, 속도, 그리고 크기의 이득을 가져오는지 분석한다.
- STR의 전형적인 도전 과제와 남아 있는 실패 사례에 대해 모듈별 기여에 대한 광범위한 분석을 제공한다.
댓글남기기