ReAct: Synergizing Reasoning and Acting in Language Models
대규모 언어 모델(LLMs)은 언어 이해와 상호작용적 의사결정 작업 전반에 걸쳐 인상적인 능력을 보여왔지만, 추론(예: 사고의 연쇄 유도)과 행동(예: 행동 계획 생성) 능력은 주로 별개의 주제로 연구되어 왔다. 본 논문에서는 추론 흔적과 작업 특화 행동을 교차하여 생성함으로써 둘 사이의 더 큰 시너지를 가능하게 하는 LLMs의 사용을 탐구한다: 추론 흔적은 모델이 행동 계획을 유도하고, 추적하며, 업데이트하는 데 도움을 주며, 예외 사항을 처리할 수 있게 해주고, 행동은 지식 베이스나 환경과 같은 외부 소스와 인터페이스하여 추가 정보를 수집할 수 있게 한다. 우리는 언어 및 의사결정 작업의 다양한 세트에 저희 접근 방식인 ReAct를 적용하고, 최신 기준 모델들을 능가하는 효과성과 추론이나 행동 구성요소 없이는 이해력이 떨어지고 신뢰성이 낮은 방법들보다 개선된 인간의 해석 가능성과 신뢰성을 입증한다. 구체적으로, 질문 응답(HotpotQA)과 사실 검증(Fever)에서, ReAct는 단순한 Wikipedia API와 상호작용함으로써 사고의 연쇄 추론에서 흔히 발생하는 환각과 오류 전파 문제를 극복하고, 추론 흔적이 없는 기준 모델들보다 더 인간 같은 작업 해결 궤적을 생성한다. 두 가지 상호작용적 의사결정 벤치마크(ALFWorld와 WebShop)에서, ReAct는 모방 및 강화 학습 방법을 각각 34%와 10%의 절대 성공률로 능가하면서, 오직 한 두 개의 문맥 예시만으로 유도되었다. 프로젝트 사이트 및 코드: this https URL
📋 Table of Contents
- 1 INTRODUCTION
- 2 REACT: SYNERGIZING REASONING + ACTING
- 3 KNOWLEDGE-INTENSIVE REASONING TASKS
- 4 DECISION MAKING TASKS
- 5 RELATED WORK
- 6 CONCLUSION
- A ADDITIONAL RESULTS
- B EXPERIMENT DETAILS
1 INTRODUCTION
- 인간 지능의 독특한 특징은 과제 지향적 행동과 언어적 추론을 결합하는 능력이다.
- 추론과 행동의 결합을 위해 새로운 과제를 빠르게 배우고, 정보 불확실성 하에서 견고한 의사결정과 추론을 가능하게 한다.
- 자율 시스템의 발전은 언어적 추론과 상호 작용적 의사결정을 결합할 수 있는 가능성을 보여준다.
- ReAct 패러다임은 언어 모델을 사용하여 추론과 행동을 결합하는 일반적인 방법이다.
- 실증 평가를 위해 ReAct는 다양한 벤치마크(HotPotQA, Fever, ALFWorld, WebShop)에서 성능을 평가받는다.
- ReAct는 기존 행동 생성 모델과 CoT 추론 모델을 능가하거나 경쟁한다.
- 전반적으로 가장 좋은 접근 방식은 추론 중에 내부 지식과 외부에서 얻은 정보를 모두 사용할 수 있게 하는 ReAct와 CoT의 조합이다.
- 인간이 모델의 내부 지식과 외부 환경 정보를 구분하고, 추론 흔적을 통해 의사결정 기반을 이해(모델 해석)할 수 있게 한다.
- 본 논문의 contribution은 ReAct의 도입, 다양한 벤치마크에서의 실험 수행, 추론과 행동의 결합 중요성 분석, ReAct의 한계 및 개선 가능성을 탐구한다.
- 향후 ReAct는 더 많은 과제에 적용되고, 강화 학습과 같은 패러다임과 결합하여 대규모 언어 모델의 잠재력을 발휘할 수 있다.
2 REACT: SYNERGIZING REASONING + ACTING
- 일반적인 에이전트는 환경으로부터 관찰을 받고, 정책에 따라 행동을 취한다.
- 컨텍스트와 행동 사이의 매핑(ct→ at)이 암시적이고 복잡한 계산을 요구한다.(Fig 1(1c), Fig 1(2a))
- ReAct의 기본 아이디어는 에이전트의 행동 공간(A)을 언어 공간(L)과 결합하여 확장(A ∪ L)한다.
- 언어 공간에서의 행동(생각 또는 추론 흔적)은 외부 환경에 영향을 주지 않아 관찰 피드백을 유발하지 않는다.
- 생각은 현재 컨텍스트에 대한 추론을 통해 유용한 정보를 구성하고 컨텍스트를 업데이트한다.(Fig 1(1d), Fig 1(2b))
- 언어 공간이 무한하므로 학습이 어렵고 강력한 언어 사전 지식이 필요하므로, 고정된 대규모 언어 모델(PaLM-540B) 사용했다.
- 도메인별 행동과 자유 형식 언어 생각 생성을 위한 몇 가지 사례를 포함한 컨텍스트 예시로 프롬프트해야한다.
- ReAct의 독특한 특징:
- A) 직관적이고 설계하기 쉬움: 인간 주석자들이 행동을 취한 후에 그들의 생각을 언어로 타이핑
- B) 일반적이고 유연함: 다양한 과제에 적용 가능 (QA, 사실 검증, 텍스트 게임, 웹 탐색 등)
- C) 성능이 뛰어나고 강건함: 새로운 과제 인스턴스에 대한 강력한 일반화 및 다른 도메인에서 기존 기준을 능가하는 성능
- D) 인간과 일치하고 제어 가능함: 추론 및 사실 정확성 검사가 용이하고, 인간이 생각 편집을 통해 에이전트 행동을 제어하거나 수정 가능

3 KNOWLEDGE-INTENSIVE REASONING TASKS
3.1 SETUP
- Domains
- 두 가지 데이터셋, 지식 검색과 추론에 도전적인 것을 고려한다.
- (1) HotPotQA(Yang et al., 2018): 멀티 홉 질문 응답 벤치마크이다. 두 개 이상의 위키피디아 글에서 추론이 필요하다.
- (2) FEVER(Thorne et al., 2018): 사실 검증 벤치마크이다. 각 주장은 SUPPORTS, REFUTES, 또는 NOT ENOUGH INFO로 주석이 달려 있으며, 위키피디아 글을 통해 주장을 검증할 수 있는지에 따라 결정된다.
- 두 과제 모두 모델은 지원 문단에 접근하지 않고 질문/주장만 설정으로 운영된다
- 내부 지식을 활용하거나 외부 환경과 상호 작용하여 지식을 검색함으로써 추론을 지원해야한다.
- 두 가지 데이터셋, 지식 검색과 추론에 도전적인 것을 고려한다.
- Action Space
- 세 가지 유형의 행동이 있는 위키피디아 웹 API를 통해 상호 작용적 정보 검색을 지원한다.
- (1) search[entity] 행동: 해당 entity 위키 페이지에서 처음 5개 문장을 반환하거나, 존재하지 않을 경우 상위 5개 유사 entity를 제안한다.
- (2) lookup[string] 행동: 페이지에서 string이 포함된 다음 문장을 반환하며, 부라우저의 Ctrl+F 기능을 모방한다.
- (3) finish[answer] 행동: 현재 과제를 answer로 마무리한다.
- 이 행동 공간은 대부분 글의 일부만 검색할 수 있으며, SOTA lexical or neural retrievers보다 약하다.
- 목적은 사람들이 위키피디아와 어떻게 상호 작용하는지 모방하고, 모델이 언어로 명시적 추론을 통해 검색하도록 한다.
- 세 가지 유형의 행동이 있는 위키피디아 웹 API를 통해 상호 작용적 정보 검색을 지원한다.
3.2 METHODS
- ReAct Prompting
- 학습 세트에서 무작위로 HotpotQA는 6개, Fever는 3개의 사례를 선택한다.
- ReAct 형식의 궤적(trajectory)을 수동으로 구성하여 프롬프트에서 few-shot exemplars로 사용한다.
- 각 궤적은 여러 생각-행동-관찰 단계(i.e. dense thought)로 구성된다(Fig 1(d)).
- 질문 분해, 위키피디아 관찰에서 정보 추출, 상식 및 산술적 추론, 검색 재구성 가이드, 최종 답변 종합 등의 다양한 목적으로 생각을 사용한다.
- ① 질문 분해: “I need to search x, find y, then find z”
- ② 위키피디아 관찰에서 정보 추출: x was started in 1844”, “The paragraph does not tell x”
- ③ 상식: “x is not y, so z must instead be…”
- ④ 산술적 추론: “1844 < 1989”
- ⑤ 검색 재구성 가이드: “maybe I can search/look up x instead”
- ⑥ 최종 답변 종합: “…so the answer is x”
- Baselines
- ReAct 궤적을 축소(ablate)하여 여러 기준선을 구축한다(Fig 1(1a-1c)).
- (a) Standard prompting(Standard): ReAct 궤적에서 모든 생각, 행동, 관찰을 제거한다.
- (b) Chain-of-thought prompting(CoT): 행동과 관찰을 제거하고 추론만을 위한 기준선으로 사용한다. 또한 기존 CoT보다 성능을 향상된 CoT-SC(Self-Consistency)을 활용한다.
- (c) Acting-only prompt(Act): 생각을 제거하며, WebGPT와 유사한 방식으로 인터넷과 상호 작용하지만, 다른 작업 및 행동 공간에서 운영되며 프롬프트 대신 모방과 강화 학습을 사용한다.
- ReAct 궤적을 축소(ablate)하여 여러 기준선을 구축한다(Fig 1(1a-1c)).
- Combining Internal and External Knowledge
- ReAct는 문제 해결 과정이 더 사실적이고, 구체적이며, CoT는 추론 구조를 형성하는데 더 정확하지만 환각 문제가 남아있다.
- 따라서, ReAct와 CoT-SC를 결합한다.
- A) ReAct → CoT-SC: ReAct 답변 실패 시 CoT-SC로 back off한다.
- B) CoT-SC → ReAct: n개의 CoT-SC 샘플 중 다수의 답변이 n/2회 미만(즉, 내부 지식이 과제를 확실히 지원하지 못할 수 있음.)이면 ReAct로 back off한다.
- Finetuning
- 대규모 수동 주석의 어려움으로 부트스트래핑 접근 방식(Zelikman et al. (2022))을 고려한다.
- ReAct가 생성한 3,000개의 정확한 답변이 포함된 궤적을 사용한다.
- PaLM-8/62B와 같은 더 작은 언어 모델을 미세 조정하여 입력 질문/주장에 조건을 달고 궤적(모든 생각, 행동, 관찰)을 디코딩한다(Appendix B.1.).
3.3 RESULTS AND OBSERVATIONS
- ReAct outperforms Act consistently
- ReAct는 Act보다 일관되게 우수하다.
- aLM-540B를 기반 모델로 사용한 HotpotQA와 Fever에서 ReAct는 Act보다 추론을 사용하여 행동을 안내하고 최종 답변을 종합하는 데 효과적이다.(Fig 1(1c-d))
- ReAct vs. CoT
- Fever에서는 ReAct가 CoT보다 우수하다(60.9 vs. 56.3).
- HotpotQA에서는 ReAct가 CoT에 약간 뒤진다(27.4 vs. 29.4).
- Fever의 SUPPORTS/REFUTES 주장은 약간의 차이로만 다를 수 있으므로, 정확하고 최신의 지식을 검색하는 것이 중요하다.
- HotpotQA에서 ReAct와 CoT의 행동 차이를 이해하기 위해 성공 및 실패 모드를 수동으로 라벨링한다.
- A) CoT에 대한 환각 문제가 심각하며, success 모드에서 ReAct보다 훨씬 높은 false positive 비율(14% 대 6%)을 초래하며 주된 failure 모드(56%)를 구성한다.
- B) ReAct는 구체적이고 신뢰할 수 있지만, CoT보다 추론 단계를 형성하는 유연성이 떨어진다. ReAct의 주요 오류 패턴은 모델이 이전 생각과 행동을 반복적으로 생성한다.
- C) ReAct에서는 유익한 지식을 성공적으로 검색하는 것이 중요하며, 에러 케이스의 23%를 차지하는 비정보적 검색(non-informative search)은 추론 오류의 주요 원인이다.
- Appendix E.1에서 각 succes와 failure 모드의 예시 제공한다.
- ReAct + CoT-SC perform best for prompting LLMs
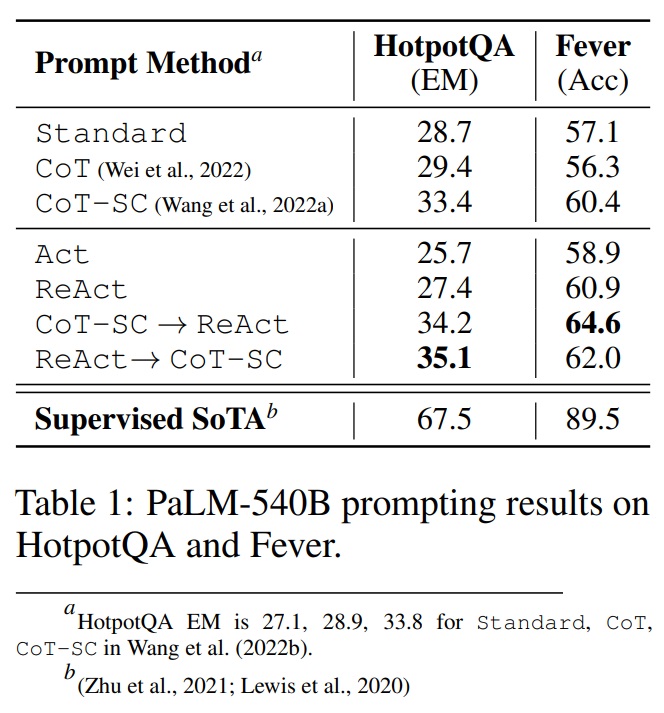
- HotpotQA와 Fever에서 최상의 프롬프트 방법은 각각 ReAct → CoT-SC와 CoT-SC → ReAct이다.(Table 1)
- ReAct와 CoT-SC를 결합한 두 가지 접근 방법은 각각의 과제에서 효과적이며, CoT-SC를 단독으로 사용할 때보다 샘플 수에 관계없이 일관되게 더 높은 성능을 보인다.(Fig 2)
Fig 2 펼치기/접기
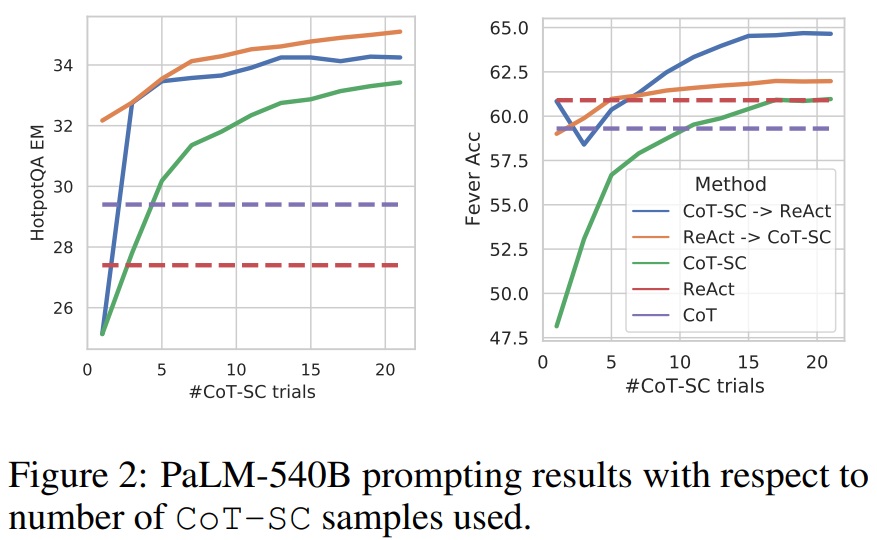
Table 1 펼치기/접기
- ReAct performs best for fine-tuning
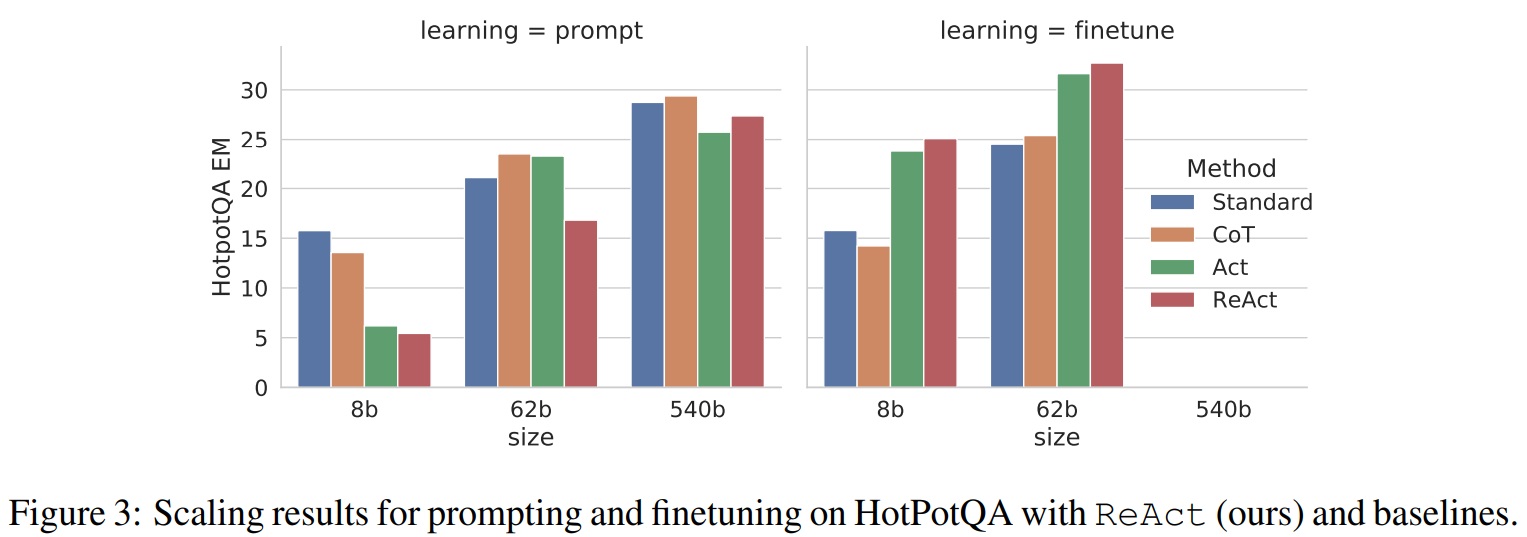
- 네 가지 방법(표준, CoT, Act, ReAct)을 HotpotQA에서 프롬프트/미세 조정하는 스케일링 효과를 보여준다.(Fig 3)
- PaLM-8/62B에서 ReAct 프롬프트가 상대적으로 성능이 낮지만, 3,000개의 예시로 미세 조정하면 가장 좋은 방법이 된다.
- PaLM-8B 미세 조정 ReAct가 모든 PaLM-62B 프롬프트 방법을, PaLM-62B 미세 조정 ReAct가 모든 PaLM-540B 프롬프트 방법을 능가한다.
- ReAct가 더 뛰어날 수 있는 방법은 더 많은 human-written data로 미세 조정하는 것이다.
Fig 3 펼치기/접기
4 DECISION MAKING TASKS
- ALFWorld
- ALFWorld(Shridhar et al., 2020b)(Fig 1(2))는 구체화된 ALFED 벤치마크(Shridhar et al., 2020a)와 일치하도록 설계된 합성 텍스트 기반 게임이다.
- 에이전트가 텍스트 행동을 통해 가상의 가정집을 탐색하고 상호 작용하여 고차원 목표를 달성해야 한다.
- 6가지 유형의 과제를 포함한다. 예를 들어, “examine paper under desklamp” 같은 고차원 목표를 달성한다.
- 과제 인스턴스로는 50개 이상의 위치를 포함하며, 전문가 정책으로 해결하는 데 50단계 이상이 필요하다.
- LLM의 적용하는 것은 사전 학습된 상식 지식을 활용하는 데 적합하다.
- ReAct 프롬프트를 생성하기 위해 각 과제 유형별로 3개의 궤적을 주석하고 각 궤적은 목표 분해, 부목표 완성 추적, 다음 부목표 결정, 객체 찾기 및 활용에 대한 상식적 추론을 포함한다.
- 134개의 보이지 않는 평가 게임에서 과제별 설정으로 평가한다.
- 각 과제 유형별로 6개의 프롬프트를 구성한다.
- Baseline으로는 BUTLER (Shridhar et al., 2020b)를 사용한다. 이는 각 과제 유형에 대해 10^5 전문가 궤적으로 훈련된 모방 학습 에이전트이다.
- WebShop
- 온라인 쇼핑 웹사이트 환경인 WebShop을 조사한다.
- WebShop은 1.18M개의 실제 제품과 12k개의 인간 지시사항을 포함한다.
- ALFWorld와 달리 구조화된 텍스트와 비구조화된 텍스트(예: 제품 제목, 설명, Amazon에서 크롤링한 옵션)를 포함한다.
- 에이전트는 웹 상호 작용을 통해 사용자 지시사항에 따라 제품을 구매해야 한다.
- 이 과제는 평균 점수(선택된 제품이 모든 에피소드에서 평균적으로 커버하는 원하는 속성의 백분율)와 성공률(선택된 제품이 모든 요구 사항을 충족하는 에피소드의 백분율)로 평가된다.
- Act 프롬프트는 검색, 제품 선택, 옵션 선택, 구매 등의 행동으로 구성한다.
- ReAct 프롬프트는 추가적으로 탐색 결정, 구매 시기 결정, 지시사항과 관련된 제품 옵션 추론한다.
- Table 6에 예시 프롬프트가 있으며, 모델 예측은 Appendix의 Table 10에 나와 있다.
- 1,012개의 인간 주석 궤적으로 학습된된 모방 학습(imitation learning, IL) 방법과 추가적으로 10,587개의 학습 지시사항으로 학습된 모방 + 강화 학습(IL + RL) 방법과 비교한다.
Table 6 펼치기/접기

Table 10 펼치기/접기

- Results
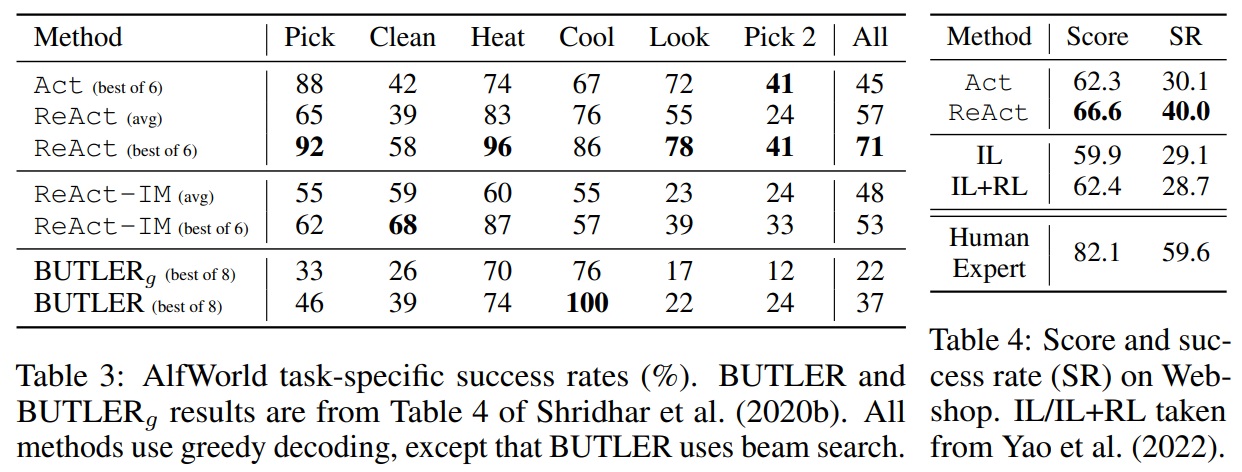
- ReAct의 성능은 ALFWorld(Table 3)와 Webshop(Table 4) 모두에서 Act를 능가한다.
- ALFWorld에서 ReAct의 최고 시도 평균 성공률이 71%로, 가장 좋은 Act 시도(45%)와 BUTLER(37%)보다 높은 성공률을 달성한다.
- ReAct의 가장 낮은 시도(48%)조차 다른 두 방법의 최고 시도보다 높다.
- 여섯 개의 제어된 시도에서 일관되게 Act를 능가하며, 상대적 성능 향상은 평균 62%(범위: 33%~90%)에 달한다. (Appendix D.2.1-2)
- Act는 목표를 작은 부목표로 올바르게 분해하지 못하거나, 환경의 현재 상태를 잃어버린다.
- Webshop에서는 한 번의 Act 프롬프트만으로도 IL 및 IL+RL 방법과 비슷한 성능을 보인다.
- Webshop에서 추가적인 희소한 추론을 통해 ReAct는 이전 최고 성공률보다 절대적으로 10% 향상된 성능을 보인다.
- 잡음이 많은 관찰과 행동 사이의 격차를 추론하여 지시사항 관련 제품과 옵션을 더 잘 식별한다.
- Webshop에서 기존 방법들은 전문가 수준의 인간 성능에 크게 못 미치며(Table 4), 더 많은 제품 탐색 및 쿼리 재구성이 여전히 도전적이다.
Table 3,4 펼치기/접기
- On the value of internal reasoning vs. external feedback
- ReAct는 대화형 환경에서 LLM을 사용한 결합된 추론과 행동을 달성하는 첫 번째 시도이다.
- 유사한 연구인 Inner Monologue(IM)의 “inner monologue”는 환경 상태의 관찰과 에이전트가 목표를 달성하기 위해 완료해야 할 사항에 제한되는 한계가 있다.
- 반면에, ReAct는 의사결정을 위해 유연하고 희소하며, 다양한 추론 유형을 다른 과제에 유도할 수 있다.
- IM과 유사한 밀집된 외부 피드백으로 구성된 생각 패턴을 사용하여 축소 실험(ablation experiment)을 수행했다.
- ReAct는 IM 스타일 프롬프트(ReAct-IM)를 크게 능가한다(전체 성공률 71 vs. 53).
- ReAct는 여섯 과제 중 다섯 과제에서 일관된 이점을 보여준다.
- ReAct-IM의 문제로는 고차원 목표 분해 부족으로 인해 부목표 완료 여부와 다음 부목표 식별에서 실수를 자주 범한다.
- ReAct-IM 궤적은 ALFWorld 환경 내에서 항목 위치를 결정하는 데 어려움을 겪는다. 이는 상식적 추론 부족으로 인한 것이다.
- 이러한 단점들은 ReAct 패러다임에서 해결할 수 있다.
- ReAct-IM에 대한 자세한 내용은 Appendix B.2에, 예시 프롬프트는 Appendix C.4에, 예시 궤적은 Appendix D.2.3에 있다.
5 RELATED WORK
- Language model for reasoning
- 가장 잘 알려진 LLM을 이용한 추론 작업은 Chain-of-Thought (CoT)로, 문제 해결을 위한 자체 “사고 절차”를 형성하는 LLM의 능력을 보여준다.
- 이후의 후속 연구로는 least-to-most prompt(Zhou et al., 2022), zero-shot-CoT (Kojima et al., 2022), reasoning with self-consistency (Wang et al., 2022a) 등이 있다.
- Madaan & Yazdanbakhsh, 2022에서는 CoT의 구성과 구조를 체계적으로 연구한다.
- 복잡한 추론 아키텍처로 확장된 연구로는 Selection-Inference, STaR, Faithful reasoning 등이 있으며, 각 단계별로 LM을 사용한다.
- Language model for decision making
- WebGPT는 웹 브라우저와 상호 작용하고 복잡한 질문에 답하는 LM을 사용한다. 웹 페이지를 탐색하며, ELI5 (Fan et al., 2019)에서 복잡한 질문에 대한 답을 추론한다.
- WebGPT의 한계는 사고 및 추론 절차를 명시적으로 모델링하지 않고, 강화 학습을 위해 비용이 많이 드는 인간 피드백에 의존한다.
- 대화 모델링은 BlenderBot, Sparrow, SimpleTOD 등이 API 호출에 대한 의사결정을 위해 LM을 학습한다.
- 대화 모델링의 한계는 명시적으로 추론 절차를 고려하지 않으며, 정책 학습을 위해 비싼 데이터 세트와 인간 피드백 수집에 의존한다.
- ReAct는 추론 절차의 언어 설명만 필요하기 때문에 훨씬 저렴한 방법으로 정책을 학습한다.
- LLM은 계획 및 의사결정을 위해 대화형 및 신체화된 환경에서 점점 더 많이 활용되고 있다.
- SayCan과 Inner Monologue은 로봇 행동 계획 및 의사결정을 위한 LLM 사용한다.
- 화형 의사결정 과정에서 언어를 의미론적으로 풍부한 입력으로 활용한다.
- LLM의 영향으로 언어는 대화 및 의사결정에서 중요한 인지 메커니즘이 되고 있다.
- LLM의 발전은 다재다능하고 일반적인 에이전트 개발에 영감을 준다.
6 CONCLUSION
- 대규모 언어 모델에서 추론과 행동을 시너지하게 하는 방법인 ReAct의 제안한다.
- 멀티 홉 질문 응답, 사실 확인, 대화형 의사결정 등 다양한 과제에서 실험을 진행한다.
- ReAct는 해석 가능한 의사결정 흔적을 가지면서 우수한 성능을 보인다.
- 큰 행동 공간을 가진 복잡한 과제는 더 많은 시연이 필요하며, 입력 길이 제한을 초과할 수 있다는 학습의 한계가 있다.
- 미세 조정 접근법으로 HotpotQA에서 초기 유망한 결과를 보이나, 더 많은 고품질 인간 주석으로부터 학습하는 것이 필요하다.
- 다중 과제 훈련으로 확장하고 강화 학습과 같은 보완적인 패러다임과 결합할 필요가 있다.
- 더 강력한 에이전트를 통해 LLM의 더 많은 응용 분야에서의 잠재력을 발휘할 수 있다.
A ADDITIONAL RESULTS
A.1 GPT-3 EXPERIMENTS
- 실험 수행: 추가적인 GPT-3 실험을 수행했다.
- 성능 확인: ReAct 프롬프팅 성능이 다양한 대규모 언어 모델에서 일반적임을 확인했다.
- GPT-3의 우수성: GPT-3은 HotpotQA와 ALFWorld에서 PaLM-540B를 일관되게 능가한다.
- 미세 조정의 영향: GPT-3의 성능이 human instruction에 따른 미세 조정 때문일 수 있다.
- 효과적인 프롬프팅: ReAct 프롬프팅이 다양한 과제에서 다른 대규모 언어 모델에 효과적임을 나타낸다.
- 코드 제공: 실험에 대한 코드는 https://react-lm.github.io/ 에서 제공된다.
A.2 REAC T OBTAINS UP-TO-DATE KNOWLEDGE ON HOTPOTQA
- Trajectory inspection 중에 ReAct가 데이터셋 라벨과 일치하지 않는 경우도 발견된다.
- 라벨 자체가 오래되었을 수 있다.
- Standard와 CoT는 환각으로 인해 잘못된 답변을 제공한다.
- Act는 추론 부족으로 잘못된 답변을 제공한다.
- 최신 정보의 검색: 오직 ReAct만이 인터넷에서 최신 정보를 검색할 수 있다.
- ReAct는 합리적인 답변을 제공한다.
A.3 HUMAN-IN-THE-LOOP BEHAVIOR CORRECTION ON ALFWORLD
- ReAct와의 인간 참여 상호 작용을 탐구하여 인간이 ReAct의 추론 흔적을 검사하고 편집할 수 있게 한다.
- Fig 5와 같이 Act 17의 문장을 제거하고 Act 23에 힌트를 추가하여 ReAct의 행동을 변경할 수 있다.
- 인간이 모델 매개변수를 변경할 수 없으므로 Act와 이전 RL 방법에 비해 좋다.
- React의 thought를 편집하면 모델의 내부 신뢰, 추론 스타일 등 수정할 수 있다.

B EXPERIMENT DETAILS
B.1 HOTPOTQA FINETUNING DETAILS
- 배치 크기 64를 사용한다.
- PaLM-8B에서의 미세 조정: ReAct와 Act 방법은 4,000단계, Standard와 CoT 방법은 2,000단계 동안 수행한다.
- PaLM-62B에서의 미세 조정: ReAct와 Act 방법은 4,000단계, Standard와 CoT 방법은 1,000단계 동안 수행한다.
댓글남기기