Soft Teacher: End-to-End Semi-Supervised Object Detection with Soft Teacher
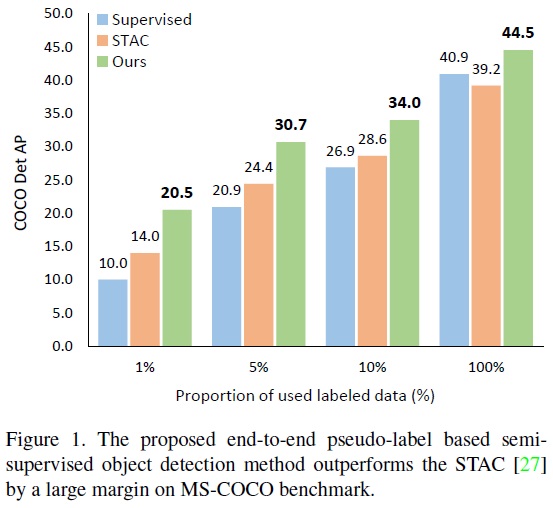
본 논문은 이전의 복잡한 다단계 방법과 다르게 처음부터 끝까지 하나의 과정으로 이루어진 준지도학습 기반 객체 탐지 접근법을 제시한다. 이 방법은 커리큘럼 동안 점차적으로 가상 레이블의 품질을 향상시키며, 점점 더 정확해진 가상 레이블은 다시 객체 탐지 학습에 이점을 제공한다. 이 프레임워크 내에서 두 가지 간단하지만 효과적인 기술을 제안한다: 각 레이블되지 않은 바운딩 박스의 분류 손실을 교사 네트워크가 생성한 분류 점수로 가중치를 두는 Soft Teacher 메커니즘; 박스 회귀 학습을 위한 신뢰할 수 있는 가상 박스를 선택하는 Box Jittering 접근법이다. COCO 벤치마크에서 제안된 접근법은 다양한 레이블링 비율(예: 1%, 5%, 10%)에서 이전 방법들을 큰 차이로 능가한다. 또한, 레이블된 데이터의 양이 상대적으로 많을 때도 잘 작동한다. 예를 들어 전체 COCO 학습 세트를 사용하여 학습된 40.9 mAP 기준 검출기를 COCO의 123K 레이블되지 않은 이미지를 활용하여 +3.6 mAP로 향상시켜 44.5 mAP에 도달할 수 있다. 최신 Swin Transformer 기반 객체 탐지기(테스트-데브에서 58.9 mAP)에서도 탐지 정확도를 +1.5 mAP 향상시켜 60.4 mAP에 도달하고, 인스턴스 분할 정확도를 +1.2 mAP 향상시켜 52.4 mAP에 도달하여, 새로운 최고 기록을 달성할 수 있다. Object365 사전 학습 모델과 추가로 결합하면 탐지 정확도가 61.3 mAP에 도달하고 인스턴스 분할 정확도가 53.0 mAP에 도달하여 새로운 최고 기록을 세운다.
📋 Table of Contents
1.Introduction
- 대규모 데이터셋의 레이블을 얻는 작업은 시간과 비용이 많이 소요되므로 어렵다.
- 현재 최고의 방식은 가상 레이블 기반 접근 방식이며, 다단계 학습 체계를 사용한다.
- 초기 탐지기에 의해 생성된 가상 레이블의 품질에 의해 최종 성능이 제한된다는 문제가 있다.
- 본 논문은 처음부터 끝까지의 가상 레이블 기반 준지도 객체 탐지 프레임워크를 통해 가상 레이블링과 탐지기 학습을 동시에 수행하는 방식을 제안한다.
- 학생 모델은 탐지 학습을 수행하고 학생 모델의 지수 이동 평균(EMA)인 교사 모델은 레이블이 없는 이미지에 가상 레이블을 주석하는 역할을 담당한다.
- 가상 레이블링과 탐지 학습 과정이 서로 상호 강화하여 학습이 진행됨에 따라 둘 다 개선된다는 플라이휠 효과가 있다.
- 교사 모델을 사용하여 학생 모델에 의해 생성된 박스 후보를 직접 평가하고, 더 광범위한 감독 정보를 학생 모델 학습에 사용하는 Soft Teacher 접근 방식을 채택한다.
- 신뢰도 측정을 통해 학생의 위치 지정 분기 학습에 사용될 신뢰할 수 있는 경계 박스를 선택하는 Box Jittering 접근 방식을 사용한다.
- MS-COCO 객체 탐지 벤치마크에서 이전 최고 방법보다 상당히 높은 성능을 달성한다.
- 레이블이 충분한 데이터셋에서도 제안된 접근 방식이 성능을 개선함을 추가 평가를 통해 확인한다.
- Object365 사전 학습 모델과 결합하여 탐지 정확도와 인스턴스 분할 정확도에서 새로운 최고 기록을 달성한다.
2.Related works
- Semi-supervised learning in image classification
- 이미지 분류에서 준지도 학습은 두 가지 주요 그룹으로 분류된다: consistency based(일관성 기반 방법) and pseudolabel based(가상 레이블 기반 방법)
- Consistency based(일관성 기반 방법)
- 레이블이 없는 이미지를 사용하여 같은 이미지의 다른 변형이 유사한 예측을 생성하도록 유도하는 정규화 손실을 구성한다.
- 변형 구현 방법에는 모델 변형, 이미지 증강, 적대적 학습 등이 포함된다.
- 예: 다른 학습 단계를 예측하여 학습 목표를 조립하는 방법, 모델 예측 대신 모델 자체를 앙상블하는 방법 등이 있다..
- Pseudolabel based(also named as self-training)(가상 레이블 기반 방법)
- 초기에 학습된 분류 모델로 레이블이 없는 이미지에 가상 레이블을 주석하고, 이 가상 레이블이 붙은 이미지로 탐지기를 세밀하게 조정한다.
- 객체 탐지에 초점을 맞춘 본 연구의 방법과 달리, 이미지 분류 시 전경/배경 레이블 할당과 박스 회귀 문제를 해결할 필요가 없다.
- 준지도 학습에서 데이터 증강의 중요성을 탐구하는 최근 연구들이 있으며, 이는 가상 레이블 생성을 위한 약한 증강과 탐지 모델 학습을 위한 강한 증강의 사용을 제안한다.
- Semi-supervised learning in object detection
- 준지도 객체 탐지 방법은 두 가지 그룹로 분류된다:consistency methods(일관성 방법), pseudo-label methods(가상 레이블 방법)
- pseudo-label methods(가상 레이블 방법)의 예
- 다양한 데이터 증강의 예측을 앙상블하여 레이블이 없는 이미지에 대한 가상 레이블을 형성한다.
- SelectiveNet을 학습시켜 가상 레이블을 선택한다.
- 레이블이 없는 이미지에서 탐지된 박스를 레이블이 있는 이미지에 붙여서 위치 일관성 추정을 수행한다.
- 본 연구 방법에서는 가벼운 탐지 헤드만 처리된다.
- STAC(Self-Training(via pseudo label) and the Augmentation driven Consistency regularization):
- 모델 학습에는 약한 데이터 증강을, 가상 레이블 수행에는 강한 데이터 증강 사용하는 것을 제안한다.
- 다단계 학습 체계를 따른다.
- 본 연구의 방법
- STAC와 다르게 종단간 가상 레이블링 프레임워크를 통해 복잡한 학습 과정을 피하고 더 나은 성능을 달성한다.
- Object Detection
- 객체 탐지는 효율적이고 정확한 탐지 프레임워크 설계에 초점을 맞춘다.
- 객체 탐지 방법에는 두 가지 주류가 있다: 단일 단계 객체 탐지기(single-stage object detectors), 이중 단계 객체 탐지기(two-stage object detectors)
- 주요 차이점은 많은 수의 객체 후보를 필터링하기 위해 캐스케이드를 사용하는지 여부에 있다.
- 이론적으로 본 연구의 방법은 두 타입의 방법 모두와 호환된다.
- 이전 연구와의 공정한 비교를 위해 기본 탐지 프레임워크로 Faster R-CNN을 사용한다.
3.Methodology
- 본 논문의 학습 프레임워크는 Fig 2와 같이 학생 모델과 교사 모델, 두 가지 모델로 구성된다.
- 학생 모델은 레이블이 있는 이미지와 레이블이 없는 이미지에서 가상 박스를 사용하여 탐지 손실로 학습한다.
- 레이블이 없는 이미지에는 분류 분기와 회귀 분기의 학습을 이끄는 두 세트의 가상 박스가 있다.
- 교사 모델은 학생 모델의 지수 이동 평균(EMA)으로, 학생 모델의 학습 과정을 안내하는 데 사용된다.
- 프레임워크 내 두 가지 중요한 설계 요소는 ‘Soft Teacher’와 ‘Box Jittering’이다. 이러한 요소들은 모델의 효율성과 정확성을 높이는 데 기여한다.
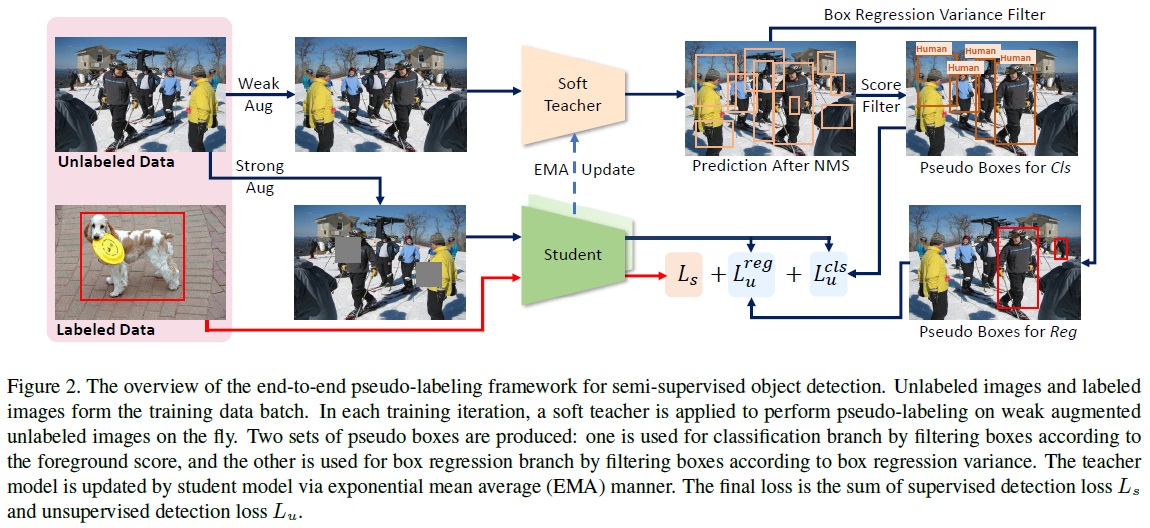
3.1.End-to-End Pseudo-Labeling Framework
- 가상 레이블링 프레임워크는 교사-학생 학습 체계를 따른다.
- 각 학습 반복에서 레이블이 있는 이미지와 레이블이 없는 이미지는 데이터 샘플링 비율에 따라 무작위로 샘플링되어 학습 데이터 배치를 형성한다.
- 전체 손실은 감독된 손실과 비감독 손실의 가중합으로 정의되며, 여기서 비감독 손실의 기여도를 조절하는 매개변수가 있다.
- 학습 시작 시 교사 모델과 학생 모델은 무작위로 초기화된다.
- 학습이 진행됨에 따라 교사 모델은 학생 모델에 의해 지속적으로 업데이트되며, 지수 이동 평균(EMA) 전략에 의해 업데이트된다.
- 객체 탐지를 위한 가상 레이블 생성은 이미지가 여러 객체를 포함하고 객체의 주석이 위치와 카테고리로 구성되기 때문에 복잡하다.
- 비최대 억제(NMS)는 중복을 제거하기 위해 수행된다.
- 임계값보다 높은 전경 점수를 가진 후보만이 가상 박스로 유지된다.
- 고품질 가상 박스를 생성하고 학생 모델의 학습을 촉진하기 위해, FixMatch의 최신 발전을 참고한다.
- 강한 증강은 학생 모델의 탐지 학습에 적용되고, 약한 증강은 교사 모델의 가상 레이블링에 사용된다.
- 프레임워크는 단일 단계 및 이중 단계 객체 탐지기에 적용 가능하다.
- 기존 연구 방법과의 공정한 비교를 위해 기본 탐지 프레임워크로 Faster R-CNN을 사용한다.
3.2.Soft Teacher
- 탐지기 성능은 가상 레이블의 품질에 의존한다.
- 실제로 높은 전경 점수 임계값을 사용하여 낮은 신뢰도를 가진 박스 후보를 필터링함으로써 더 나은 결과를 달성한다.
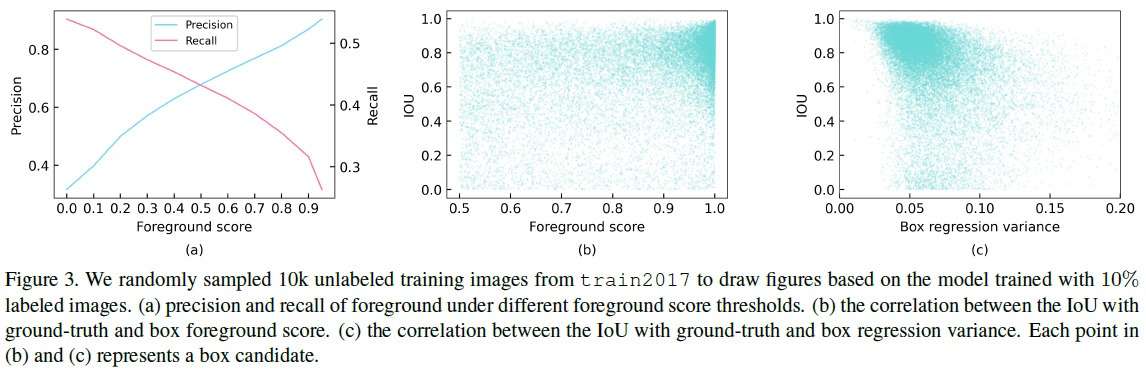
- Fig 3(a)와 같이 임계값을 0.9로 설정할 때 최고의 성능을 달성했다.
- 엄격한 기준(높은 임계값)은 전경 정밀도를 높이지만, 재현율이 빠르게 감소한다.
- 전경 임계값이 0.9일 때, 재현율은 낮지만(33%), 정밀도는 89%에 도달한다.
- 교사 모델로부터 더 풍부한 정보를 활용하여 각 학생 생성 박스 후보의 실제 배경이 될 신뢰도를 평가하고 배경 분류 손실에 가중치를 적용하는 Soft Teacher 접근 방식을 제안한다.
- 교사 모델이 생성한 배경 점수는 신뢰도의 대리 지표로 잘 작동한다.
- 다른 지표로 학생 모델의 배경 점수, 예측 차이, Intersection over Union(IoU)을 검토한다.
- 예측 차이는 학생 모델과 교사 모델 사이의 배경 점수 차이를 사용하여 정의된다.
- IoU는 전경/배경 할당에 일반적으로 사용되는 기준이다.
- IoU를 사용하여 박스 후보가 배경에 속하는지 여부를 측정하는 두 가지 다른 가설을 검증한다.
3.3.Box Jittering
- Fig 3(b)와 같이 박스 후보의 위치 정확도와 전경 점수 사이에는 강한 양의 상관관계가 없다.
- 높은 전경 점수를 가진 박스가 반드시 정확한 위치 정보를 제공하는 것은 아니다.
- 전경 점수에 따른 가상 박스의 선택은 박스 회귀에 적합하지 않으며, 위치 신뢰도를 더 잘 평가할 수 있는 새로운 기준이 필요하다.
- 후보 가상 박스의 위치 신뢰도를 측정하기 위해 교사 생성 가상 박스 주변에 지터링된 박스를 샘플링하고, 이를 교사 모델에 입력하여 박스 회귀 예측의 일관성을 평가한다.
- 교사 모델로부터 정제된 박스를 얻기 위해 지터링된 박스를 여러 번 반복 처리한다.
- 지터링된 박스를 여러 번 샘플링하여 얻은 정제된 박스 세트를 사용하여 위치 신뢰도를 박스 회귀 분산으로 정의하며, 이는 위치 신뢰도가 높을수록 작은 값을 가진다. 학습 중 모든 가상 박스 후보의 박스 회귀 분산을 계산하는 것은 불가능하므로, 전경 점수가 0.5 이상인 박스에 대해서만 신뢰도를 계산하여 계산 비용을 대폭 감소시킨다.
- 박스 회귀 분산은 위치 정확도를 잘 측정할 수 있다.
- 임계값보다 작은 박스 회귀 분산을 가진 박스 후보를 레이블이 없는 이미지에서 박스 회귀 분기 학습을 위한 가상 레이블로 선택한다.
- 레이블이 없는 데이터에 대한 박스 회귀 학습을 위한 가상 박스 사용한다.
- 레이블이 없는 이미지의 손실은 분류와 박스 회귀에 사용되는 가상 박스가 다름을 강조하여 정의된다.
4.Experiments
4.1.Dataset and Evaluation Protocol
- MS-COCO 벤치마크를 사용하여 방법을 검증한다.
- train2017(레이블이 있는 118k 이미지), unlabeled2017(레이블이 없는 123k 이미지), 검증용 val2017(5k 이미지) 세트가 제공된다.
- Partially Labeled Data는 STAC에 의해 처음 소개되며, train2017 세트의 1%, 5%, 10% 이미지를 레이블이 있는 학습 데이터로 샘플링하고, 나머지는 레이블이 없는 데이터로 사용한다.
- 성능은 5개의 다른 데이터 폴드의 평균으로 평가된다.
- Fully Labeled Data는 전체 train2017 세트가 레이블이 있는 데이터로, unlabeled2017 세트가 추가적인 레이블이 없는 데이터로 사용된다.
- 이 설정의 목표는 추가적인 레이블이 없는 데이터를 활용하여 대규모 레이블이 있는 데이터에서 잘 학습된 탐지기의 성능을 개선하는 것이다.
- 두 설정 모두에 대해 성능을 평가하며, val2017 세트에서의 성능을 표준 평균 정밀도(mAP)로 보고한다.
4.2.Implementation Details
- 실험에서는 Faster R-CNN과 Feature Pyramid Network(FPN)을 결합한 구조를 기본 탐지 프레임워크로 사용하고, 이 구조는 이미지 인식을 위해 사전 학습된 ResNet-50 백본과 함께 사용되며, MMDetection 프레임워크를 기반으로 구현된다.
- 구현과 하이퍼파라미터는 MMDetection을 기반으로 하며, 5개의 스케일과 3개의 종횡비를 가진 앵커 사용한다. 이러한 앵커는 지역 제안(region proposals) 생성 과정에서 중요한 역할을 한다.
- 학습과 추론 단계에서 각각 2,000개와 1,000개의 지역 제안을 생성하기 위해 비최대 억제(non-maximum suppression, NMS) 임계값 0.7이 적용된다.
- 각 학습 단계에서 2,000개 제안 중 512 제안을 RCNN 학습을 위한 박스 후보로 샘플링된다.
- 학습 데이터 설정
- 부분적으로 레이블된 데이터와 완전히 레이블된 데이터에 대해 다른 학습 파라미터 설정한다.
- Partially Labeled Data: 1%, 5%, 10%의 이미지가 train2017 세트에서 레이블이 있는 학습 데이터로 샘플링된다. 모델은 GPU당 5개의 이미지를 사용하여 8개의 GPU에서 180k 번의 반복으로 학습된다. 학습률은 초기에 0.01로 설정되고, 110k 번째와 160k 번째 반복에서 10분의 1로 감소됩니다.
- Fully Labeled Data: 전체 train2017 세트가 레이블이 있는 데이터로 사용ehls다. 모델은 GPU당 8개의 이미지를 사용하여 8개의 GPU에서 720k 번의 반복으로 학습된다. 학습률은 480k 번째와 680k 번째 반복에서 10분의 1로 감소된다.
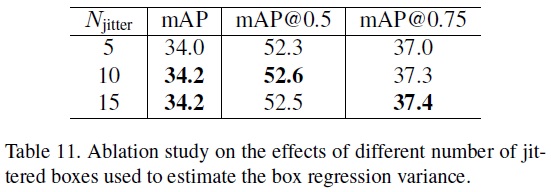
- 박스 위치 신뢰도 추정을 위해 $N_(jitter)$를 10으로 설정하고, 박스 회귀를 위한 가상 레이블로 선택하기 위한 임계값을 0.02로 설정한다.
- 지터링된 박스는 가상 박스 후보의 높이나 너비의 [-6%, 6%]에서 무작위로 샘플링된 오프셋을 추가하여 생성된다.
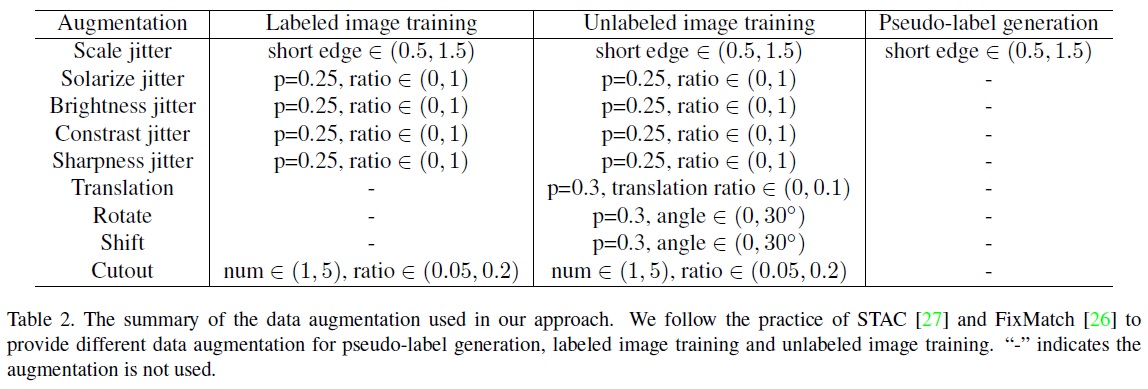
- Table 2와 같이 가상 레이블 생성, 레이블된 이미지 학습 및 레이블이 없는 이미지 학습에 대해 다른 데이터 증강 전략을 사용한다. 이는 STAC과 FixMatch가 사용하는 방식을 따른다.
4.3.System Comparison
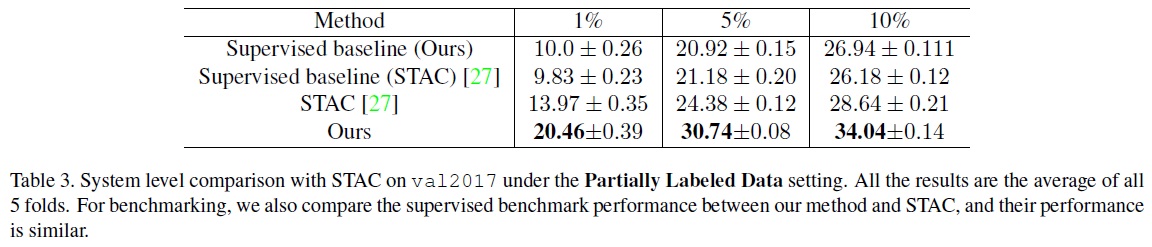
- Partially Labeled Data
- 본 연구의 방법은 STAC과 비교하여 1%, 5%, 10%의 레이블된 데이터에 대해 각각 6.5 points, 6.4 points, 5.4 points의 성능 향상을 보여준다.
- Table 3과 같이 감독된 기준선과의 비교에서 Soft Teacher와 STAC이 비슷한 성능을 보이나, 제안된 방법이 시스템 수준에서 상당한 성능 향상을 제공한다.
- 질적 결과는 Fig 4와 같이 제안된 방법이 감독된 기준선과 비교하여 향상된 성능을 보여준다.
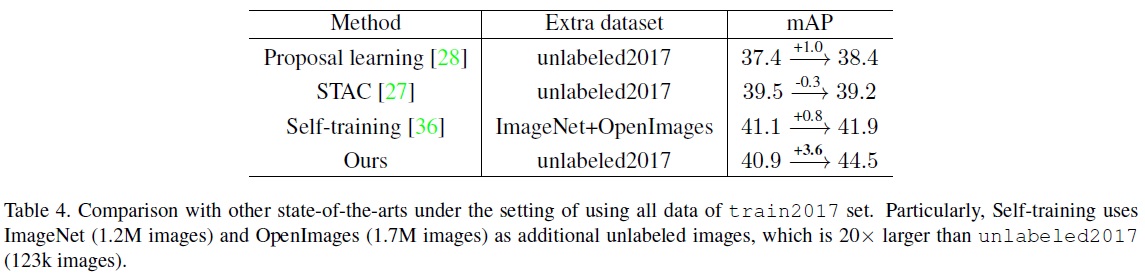
- Fully Labeled Data
- 우리의 방법은 Table 4와 같이 Proposal Learning과 STAC을 포함한 다른 최신 방법들과 비교되며, 더 나은 하이퍼파라미터와 충분한 학습으로 인해 더 강력한 기준선 성능을 달성한다.
- 제안된 방법은 더 강력한 기준선 하에서도 Proposal Learning과 STAC보다 더 큰 성능 향상을 보인다.
- Self-training과 비교할 때 더 큰 규모의 추가적인 레이블이 없는 데이터를 사용함에도 불구하고, 제안된 방법은 더 적은 레이블이 없는 데이터로 더 나은 결과를 보인다.
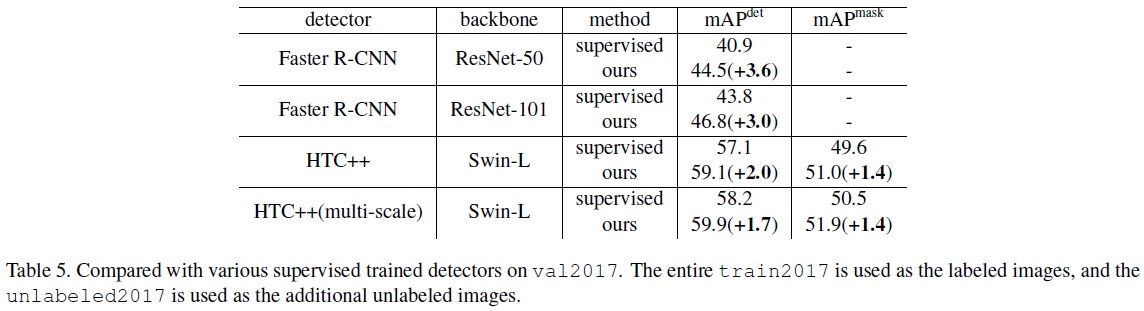
- Table 5와 같이 다양한 더 강력한 탐지기에서 제안된 방법을 평가하여 일관된 성능 개선을 보인다.
- Swin-L 백본을 가진 최신 탐지기 HTC++에서도 detection AP에서 1.8의 향상과 mask AP에서 1.4의 향상을 보여준다.
- COCO 객체 탐지 벤치마크에서 60 mAP를 초과하는 첫 번째 작업으로, HTC++와 Swin-L 백본을 사용하여 탐지에서 1.5 mAP 개선을 보고한다.

4.4.Ablation Studies
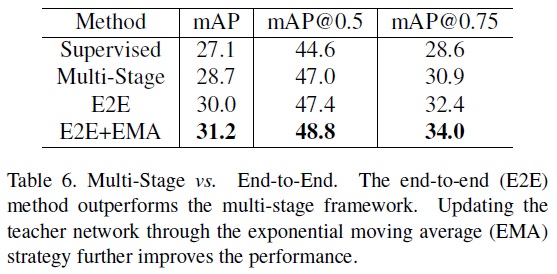
- Multi-Stage vs. End-to-End.
- 비교 결과는 Table 6와 같다.
- 다단계 프레임워크에서 종단간 프레임워크로 전환 시 1.3 points 성능 향상한다.
- 학생 모델로부터 교사 모델을 EMA 전략으로 업데이트 시 추가로 31.2 mAP 달성한다.
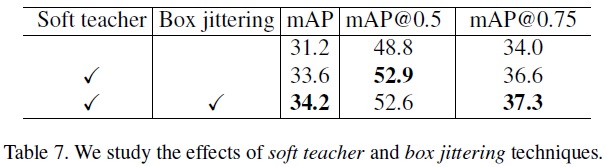
- Effects of Soft Teacher and Box Jittering.
- 결과는 Table 7과 같다.
- 본 연구의 종단간 모델(E2E+EMA)을 기반으로 Soft Teacher 통합 시 2.4 points 성능 향상한다.
- Box Jittering 추가 적용으로 34.2 mAP에 도달하여 E2E+EMA보다 3 points 향상한다.
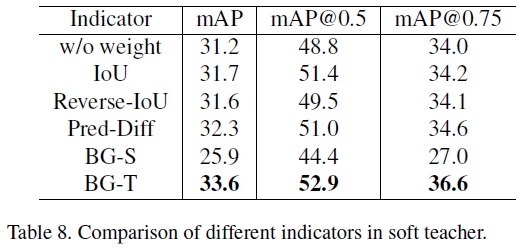
- Different Indicators in Soft Teacher.
- Table 8과 같이 교사 모델에 의해 예측된 배경 점수가 최고 성능 달성한다.
- 모델을 교사에서 학생으로 전환하면 성능 저하한다.
- IoU와 Reverse-IoU는 BG-T와 비교하여 개선 효과 미미하다. 이 결과는 교사 모델을 활용할 필요성을 입증한다.
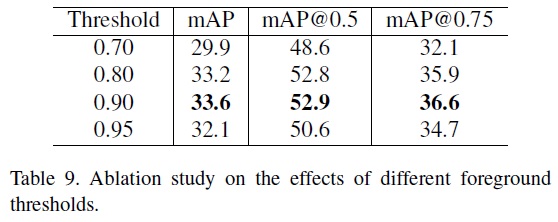
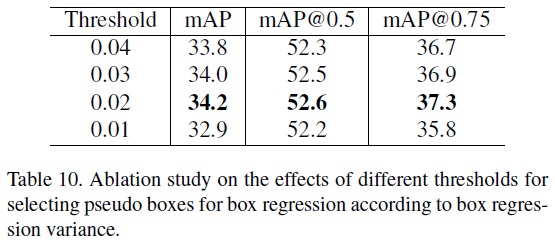
- Effects of other hyper-parameters.
- Table 9와 같이 전경 점수의 임계값을 0.9로 설정할 때 최고 성능 달성하고 더 낮거나 높은 임계값은 성능 저하 유발한다.
- Table 10과 같이 박스 회귀 분산 임계값을 0.02로 설정할 때 최고 성능 달성한다.
- Table 11과 같이 지터링된 박스의 수인 $N_(jitter)$를 10으로 설정할 때 성능이 포화상태에 도달한다.
5.Conclusion
- 이전의 복잡한 다단계 접근 방식 대신 준지도 객체 탐지를 위한 종단간 학습 프레임워크를 제안하여 프로세스의 복잡성을 줄이고 효율성을 높였다.
- 탐지 학습을 위한 학생 모델과 온라인 가상 레이블링을 위해 학생 모델에 의해 지수 이동 평균(EMA) 전략으로 지속적으로 업데이트되는 교사 모델 활용하였다.
- 지수 이동 평균 전략을 통해 탐지기와 가상 레이블을 동시에 개선했다. 이로 인해 학습 과정이 상호 강화되어 전반적인 성능이 향상된다.
- 교사 모델의 지식을 효율적으로 활용하고, 가상 레이블의 품질을 높이기 위한 Soft Teacher와 Box Jittering 기술 제시한다.
- 제안된 프레임워크가 MS-COCO 벤치마크에서 부분적으로 레이블된 데이터와 완전히 레이블된 데이터 설정 모두에서 최신 기술보다 큰 차이로 우수한 성능 달성한다.
댓글남기기