Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
이 논문은 컴퓨터 비전을 위한 범용 백본으로서 기능할 수 있는 새로운 비전 트랜스포머인 Swin Transformer를 소개한다. 언어와 비전 사이의 차이점, 예를 들어 시각적 엔티티의 규모 변화가 크고 이미지 내 픽셀의 해상도가 텍스트 내 단어에 비해 높은 점 등으로 인해 트랜스포머를 비전에 적용하는 데 있어 도전이 발생한다. 이러한 차이점을 해결하기 위해 본 논문에서는 Shifted windows로 계산된 표현을 가지는 계층적 트랜스포머를 제안한다. 이동된 창 방식은 비중첩 로컬 창으로 자기 주의 계산을 제한함으로써 효율성을 높이며, 동시에 창간 연결을 허용한다. 이 계층적 아키텍처는 다양한 규모에서 모델링할 수 있는 유연성을 가지고 있으며, 이미지 크기에 대해 선형적인 계산 복잡도를 갖는다. Swin Transformer의 이러한 특성은 이미지 분류(87.3 top-1 정확도 on ImageNet-1K)와 객체 검출(58.7 box AP와 51.1 mask AP on COCO test-dev) 및 의미 분할(53.5 mIoU on ADE20K val)과 같은 밀집 예측 작업을 포함한 다양한 비전 작업과 호환된다. 그 성능은 이전 최고 기록을 큰 차이로 초과하여 COCO에서 +2.7 box AP와 +2.6 mask AP, ADE20K에서 +3.2 mIoU를 달성함으로써, 트랜스포머 기반 모델이 비전 백본으로서의 가능성을 보여준다. 계층적 설계와 이동 창 접근 방식은 모두 MLP 아키텍처에도 유리하게 작용한다. 코드와 모델은 https://github.com/microsoft/Swin-Transformer에서 공개적으로 이용할 수 있다.
📋 Table of Contents
1. Introduction
- 컴퓨터 비전 모델링은 오랫동안 CNN(합성곱 신경망)이 주류였다.
- CNN 아키텍처는 규모의 증가, 더 많은 연결, 더 정교한 형태의 합성곱을 통해 점점 더 강력해졌다.
- 자연어 처리(NLP) 분야의 네트워크 아키텍처 진화는 Transformer가 주류 아키텍처로 다른 길을 걸었다.
- Transformer는 attention 기반으로 데이터의 long-range dependencies을 모델링하는 데 주목할 만하다.
- 연구자들은 Transformer의 컴퓨터 비전 적용 가능성을 탐구했으며, 이미지 분류와 시각-언어 모델링에서 유망한 결과를 보였다.
- 본 논문은 Transformer를 일반적인 컴퓨터 비전 백본으로 확장하고자 한다.
- 언어와 비전 도메인 사이의 차이, 특히 스케일과 이미지의 높은 해상도는 Transformer의 비전 도메인 적용에 있어 도전 과제이다.
- Swin Transformer는 계층적 특징 맵을 구축하고 이미지 크기에 대해 선형 계산 복잡성을 가진다.
- Swin Transformer는 Fig 1과 같이 계층적 표현을 구축하며, 깊은 Transformer 계층에서 인접 패치를 점진적으로 병합한다.
Fig 1 펼치기/접기
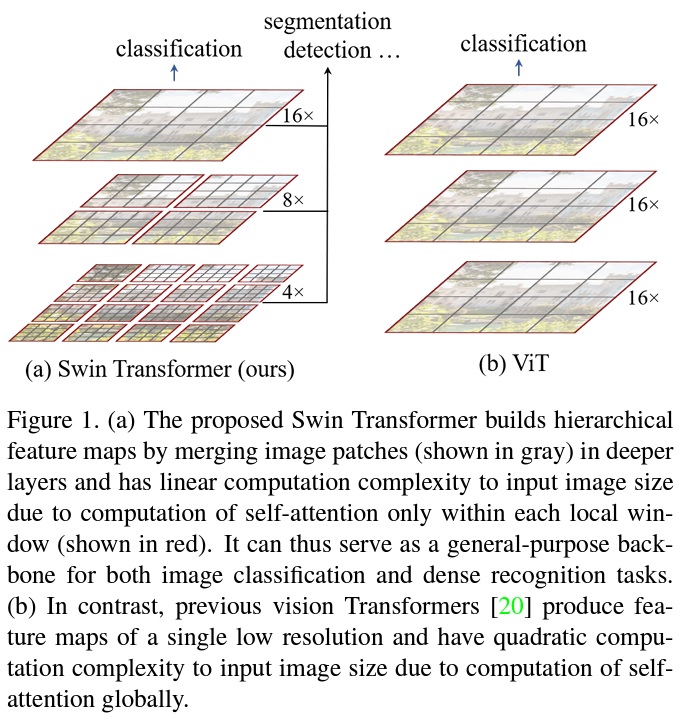
- 선형 계산 복잡성은 비중첩 윈도우 내에서 지역적으로 self-attention을 계산함으로써 달성된다.
- Swin Transformer는 다양한 비전 작업에 적합한 일반적인 백본으로 적합하다.
- Swin Transformer의 핵심 설계 요소는 Fig 2와 같이 연속 self-attention 계층 간의 윈도우 분할 이동이다.
Fig 2 펼치기/접기
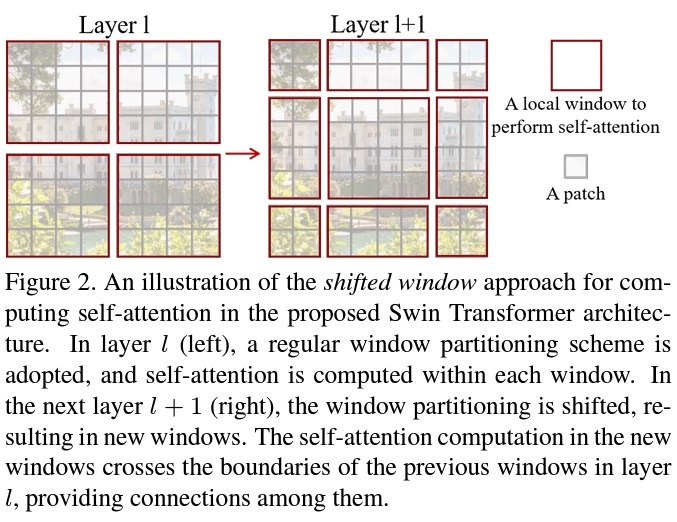
- 이동된 윈도우는 모델링 능력을 크게 향상시키며, 실제 하드웨어에서 메모리 접근을 용이하게 한다.
- Swin Transformer는 이미지 분류, 객체 탐지, 의미 분할에서 강력한 성능을 달성한다.
- 이는 ViT/DeiT와 ResNe(X)t 모델을 유사한 대기 시간으로 상당히 능가한다.
- Swin Transformer의 성능은 컴퓨터 비전과 자연어 처리 모두에 이점을 줄 수 있는 통합 아키텍처의 가능성을 제시한다.
2. Related Work
- CNN and variants
- CNN과 그 변형들은 컴퓨터 비전 전반에서 표준 네트워크 모델로 사용된다.
- CNN은 수십 년 동안 존재했지만, AlexNet의 소개로 크게 주목받기 시작했다.
- 이후 VGG, GoogleNet, ResNet, DenseNet, HRNet, EfficientNet과 같은 더 깊고 효과적인 합성곱 신경 아키텍처가 제안되었다.
- 아키텍처의 발전 외에도 depth-wise convolution, deformable convolution과 같이 개별 합성곱 계층을 개선하는 많은 작업이 이루어졌다.
- CNN과 그 변형들은 여전히 컴퓨터 비전 응용 프로그램의 주요 백본 아키텍처로 남아 있지만, 비전과 언어 간의 통합 모델링을 위한 Transformer와 같은 아키텍처의 강력한 잠재력을 강조한다.
- Self-attention based backbone architectures
- NLP 분야의 self-attention 계층과 Transformer 아키텍처의 성공에 영감을 받아, 일부 연구는 인기 있는 ResNet의 공간 합성곱 계층 일부 또는 전체를 self-attention 계층으로 대체한다.
- 이러한 연구에서는 각 픽셀의 로컬 윈도우 내에서 self-attention을 계산하여 최적화를 가속화한다.
- 이 접근 방식은 ResNet 아키텍처와 비교하여 약간 더 나은 정확도/FLOPs trade-off를 달성한다.
- 그러나 비용이 많이 드는 메모리 접근으로 인해 실제 대기 시간이 합성곱 네트워크보다 상당히 길다.
- 슬라이딩 윈도우를 사용하는 대신, 연속 계층 간에 윈도우를 이동시키는 것을 제안한다. 이는 일반 하드웨어에서 더 효율적인 구현을 가능하게 한다.
- Self-attention/Transformers to complement CNNs
- 일부 연구는 표준 CNN 아키텍처를 self-attention 계층 또는 Transformer로 보강한다.
- self-attention 계층은 백본 또는 헤드 네트워크에 장거리 의존성 또는 이질적 상호작용을 인코딩하는 능력을 제공함으로써 보완할 수 있다.
- 최근에는 Transformer의 인코더-디코더 디자인이 객체 탐지 및 인스턴스 분할 작업에 적용되었다.
- 본 연구는 기본 시각 특징 추출을 위한 Transformer의 적응을 탐구하며, 이러한 작업들과 보완적이다.
- Transformer based vision backbones
- 본 연구와 가장 관련이 깊은 것은 Vision Transformer(ViT)와 그 후속 연구들이다.
- ViT의 선구적인 작업은 이미지 분류를 위해 비중첩 중간 크기 이미지 패치에 Transformer 아키텍처를 직접 적용한다.
- ViT는 합성곱 네트워크에 비해 이미지 분류에서 인상적인 속도-정확도 trade-off를 달성한다.
- ViT는 잘 수행하기 위해 대규모 학습 데이터셋(예: JFT-300M)이 필요하지만, DeiT는 ViT가 더 작은 ImageNet-1K 데이터셋을 사용하여도 효과적일 수 있도록 여러 학습 전략을 도입한다.
- ViT의 이미지 분류 결과는 희망적이지만, 그 아키텍처는 저해상도 특징 맵과 이미지 크기에 대한 복잡도의 제곱 증가로 인해 밀집된 비전 작업이나 입력 이미지 해상도가 높을 때 일반 목적 백본 네트워크로 사용하기에 부적합하다.
- 몇몇 연구는 ViT 모델을 객체 탐지 및 의미 분할과 같은 밀집된 비전 작업에 직접 업샘플링이나 디컨볼루션을 통해 적용하지만 상대적으로 낮은 성능을 보인다.
- 본 연구와 동시에 진행된 일부 연구는 이미지 분류를 개선하기 위해 ViT 아키텍처를 수정한다.
- 경험적으로 본 연구는 이미지 분류에서 이러한 방법 중 최고의 속도-정확도 trade-off를 달성하는 Swin Transformer 아키텍처를 찾았으며, 이 연구는 분류에만 초점을 맞추기보다는 일반 목적 성능에 초점을 맞춘다.
- 다른 동시 작업은 Transformer에 다중 해상도 특징 맵을 구축하는 비슷한 사고 방식을 탐구한다. 그것의 복잡도는 여전히 이미지 크기에 대해 제곱이지만, swin-T는 선형이며 또한 지역적으로 작동하는데, 이는 시각 신호에서 높은 상관 관계를 모델링하는 데 유익하다고 입증되었다.
- 본 연구의 접근 방식은 효율적이고 효과적이며, COCO 객체 탐지 및 ADE20K 의미 분할에서 최고의 정확도를 달성한다.
3. Method
3.1. Overall Architecture
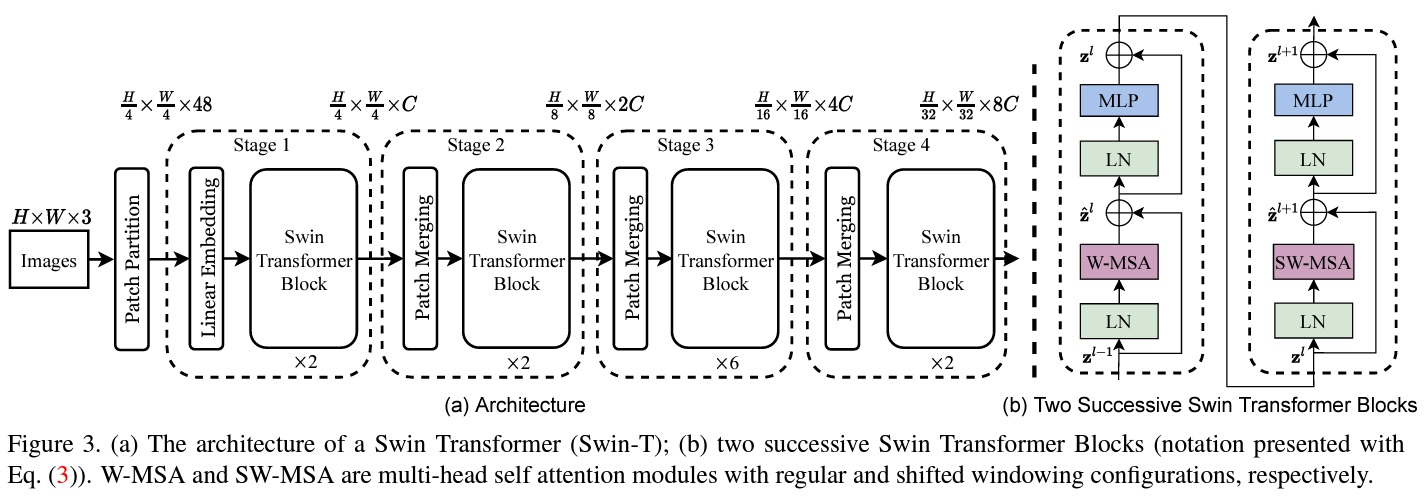
- Swin Transformer 아키텍처는 Fig 3과 같으며, 입력 RGB 이미지를 비중첩 패치로 분할하는 패치 분할 모듈로 시작한다.
- 각 패치는 “토큰”으로 취급되며, 그 특징은 raw 픽셀 RGB 값의 연결로 설정된다. 구현에서는 패치 크기를 4x4로 사용하며, 각 패치의 특징 차원은 48이다.
- raw-valued 특징에 선형 임베딩 층이 적용되어 임의의 차원(C로 표시)으로 투영된다.
- 이러한 패치 토큰에 수정된 self-attention 계산을 갖는 여러 Transformer 블록(Swin Transformer 블록)이 적용된다.
- Transformer 블록은 토큰의 수(H/4 x W/4)를 유지하며, 선형 임베딩과 함께 “Stage 1”로 언급된다.
- 계층적 표현을 생성하기 위해 네트워크가 깊어짐에 따라 패치 병합 층에 의해 토큰의 수가 줄어든다.
- 첫 번째 패치 병합 층은 2x2 인접 패치의 각 그룹의 특징을 연결하고, 4C 차원 연결된 특징에 선형 층을 적용한다.
- 이는 토큰 수를 4의 배수(해상도의 2x 다운샘플링)로 줄이고, 출력 차원은 2C로 설정된다.
- 이후 Swin Transformer 블록이 특징 변환을 위해 적용되며, 해상도는 H/8 x W/8로 유지된다.
- 이 첫 번째 패치 병합 및 특징 변환 블록은 “Stage 2”로 표시된다.
- 절차는 “Stage 3”과 “Stage 4”로 두 번 반복되며, 각각의 출력 해상도는 H/16 x W/16 및 H/32 x W/32이다.
- 이 Stage들은 VGG와 ResNet과 같은 전형적인 합성곱 네트워크의 특징 맵 해상도와 동일한 계층적 표현을 공동으로 생성한다.
- 결과적으로 제안된 아키텍처는 다양한 비전 작업을 위한 기존 방법에서 백본 네트워크를 편리하게 대체할 수 있다.
- Swin Transformer block
- Swin Transformer 블록은 표준 multi-head self attention(MSA) 모듈을 이동된 윈도우(shifted windows)를 기반으로 한 모듈로 대체함으로써 구축된다.
- Swin Transformer 블록은 이동된 윈도우 기반 MSA 모듈로 구성되며 이어서 GELU 비선형성을 가진 2-layer MLP가 따른다.
- 각 MSA 모듈과 각 MLP 전에 LayerNorm(LN) 층이 적용되며, 각 모듈 후에 residual connection이 적용된다.
3.2. Shifted Window based Self-Attention
- 표준 Transformer 아키텍처와 그 이미지 분류를 위한 적용은 모두 global self-attention을 수행한다.
- global 계산은 토큰 수에 대해 제곱 복잡성을 초래하여, 밀집 예측이나 고해상도 이미지를 표현하기 위해 방대한 토큰 세트가 필요한 많은 비전 문제에 부적합하다.
- Self-attention in non-overlapped windows
- 비중첩 윈도우 내 self-attention을 효율적인 모델링을 위해 제안한다.
- 윈도우는 이미지를 비중첩 방식으로 균등하게 분할하기 위해 배열된다.
-
각 윈도우가 MxM 패치를 포함한다고 가정하면, global MSA 모듈과 윈도우 기반 모듈의 계산 복잡도는 아래 수식과 같다.
(1) $\Omega(MSA) = 4hwC^2 + 2(hw)^2C$
(2) $\Omega(W-MSA) = 4hwC^2 + 2M^2hwC$ - global self-attention 계산은 대규모 hw에 대해 일반적으로 감당할 수 없지만, 윈도우 기반 self-attention은 확장 가능하다.
- Shifted window partitioning in successive blocks
- 이동된 윈도우 분할 접근 방식은 연속 Swin Transformer 블록에서 이전 계층의 비중첩 윈도우 간의 연결을 도입한다.
- 첫 번째 모듈은 좌상단 픽셀에서 시작하는 regular window partitioning strategy을 사용한다.
- 8 x 8 특징 맵은 4x4 크기의 2x2 창으로 균등하게 분할한다(M = 4).
- 그 다음 모듈은 이전 레이어의 창 구성에서 ($\left[ \frac{M}{2} \right], \left[ \frac{M}{2} \right]$) 픽셀만큼 창을 이동시켜 정규 분할 창에서 변화된 창 구성을 채택한다.
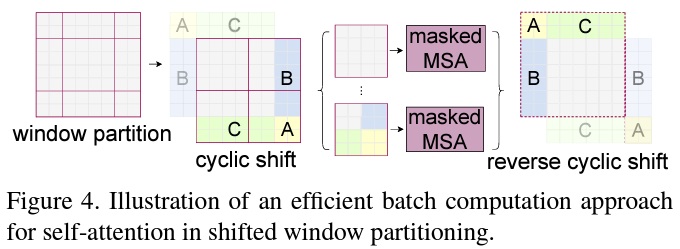
- Efficient batch computation for shifted configuration
- 이동된 윈도우 분할로 인해 더 많은 윈도우가 생성되고 일부 윈도우는 MxM보다 작게 될 수 있다.
- 이 문제를 해결하기 위해서 Fig 4와 같이 좌상단 방향으로 순환 이동하는 더 효율적인 배치 계산 접근 방식을 제안한다.
- 순환 이동으로 인해 배치된 윈도우의 수는 regular window partitioning의 수와 동일하게 유지되므로 효율적이다.
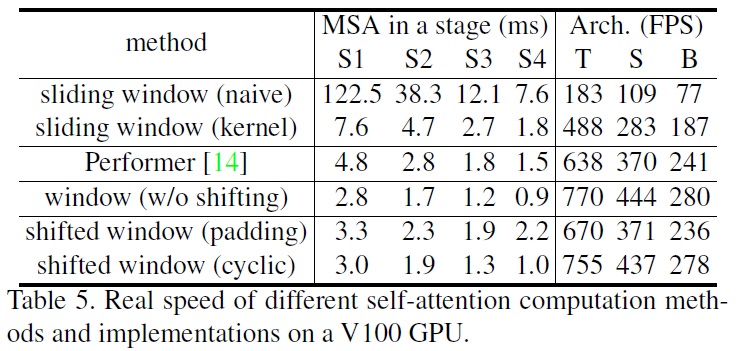
- Table 5는 이 접근법의 low latency를 보여준다.
- Relative position bias
-
self-attention 계산에서 각 헤드에 상대 위치 편향$(B \in \mathbb{R}^{M^2 \times M^2})$을 포함하여 유사도를 계산한다.
$\text{Attention}(Q, K, V) = \text{SoftMax}\left(\frac{QK^T}{\sqrt{d}} + B\right)V$
- $Q, K, V \in \mathbb{R}^{M^2 \times d}$는 쿼리, 키, 값 행렬이다.
- $d$는 쿼리/키 차원이고, $M^2$는 창 내의 패치 수이다.
- 각 축에 따른 상대 위치가 $[-M + 1; M - 1]$ 범위에 있으므로, 더 작은 크기의 편향 행렬 $\hat{B} \in \mathbb{R}^{(2M-1) \times (2M-1)}$을 매개변수화하고, $B$의 값들은 $\hat{B}$에서 가져온다.
-
3.3. Architecture Variants
- Swin-B는 ViTB/DeiT-B와 유사한 모델 크기와 계산 복잡도를 가진 기본 모델이다.
- Swin-T, Swin-S, Swin-L은 각각 모델 크기와 계산 복잡도가 약 0.25배, 0.5배, 2배인 버전이다.
- Swin-T와 Swin-S의 복잡도는 각각 ResNet-50(DeiT-S) 및 ResNet-101과 유사하다.
- 윈도우 크기는 기본적으로 M = 7로 설정된다.
- 각 헤드의 쿼리 차원은 $d$ = 32이고, 각 MLP의 확장 계층은 $\alpha$ = 4로 모든 실험에 대해 설정된다.
- 아키텍처 하이퍼파라미터는 다음과 같다:
- Swin-T: C = 96, 레이어 수 = {2, 2, 6, 2}
- Swin-S: C = 96, 레이어 수 = {2, 2, 18, 2}
- Swin-B: C = 128, 레이어 수 = {2, 2, 18, 2}
- Swin-L: C = 192, 레이어 수 = {2, 2, 18, 2}
- 여기서 C는 첫 번째 Stage의 숨겨진 레이어들의 채널 수이다.
-
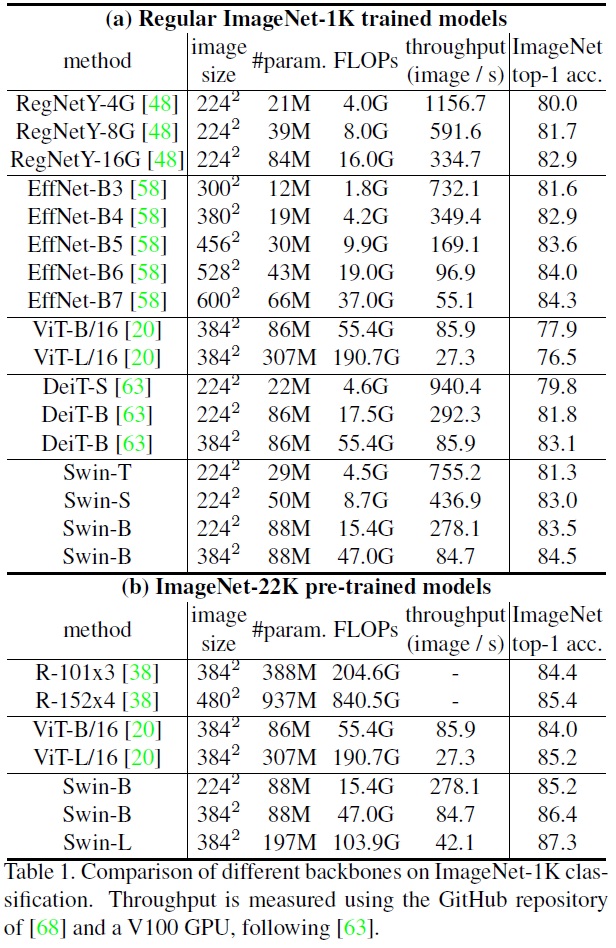
모델 변형의 크기, 이론적 계산 복잡도(FLOPs), 및 ImageNet 이미지 분류를 위한 모델의 처리량은 Table 1에 나열된다.
4. Experiments
- ImageNet-1K 이미지 분류, COCO 객체 탐지, ADE20K 의미 분할 실험을 수행한다.
- 이어서 제안된 Swin Transformer 아키텍처를 세 가지 작업에서 이전 최고의 성능과 비교한다.
4.1. Image Classification on ImageNet1K
- Settings
- ImageNet-1K에서 이미지 분류를 위한 Swin Transformer 벤치마킹을 수행한다.
- Regular ImageNet-1K training. AdamW를 사용하여 300 에폭 동안 코사인 감소 학습률 스케줄러와 20 에폭의 선형 웜업을 사용한다. 또한 배치크기 1024, 초기 학습률 0.001, 가중치 감소 0.05가 사용되며, 대부분의 증강 및 정규화 전략을 포함한다.
- Pre-training on ImageNet-22K and fine-tuning on ImageNet-1K. 더 큰 ImageNet-22K(1,420만 개 이미지와 22k 클래스 포함)에서 사전 학습 후 AdamW를 사용하여 90 에폭 동안 선형 감소 학습률 스케줄러와 5 에폭의 선형 웜원을 사용한다. 또한 배치크기 4096, 초기 학습률 0.001, 가중치 감소 0.01이 사용되며, ImageNet-1K에서 미세 조정하는 설정하기 위해 30 에폭 동안 배치크기 1024, 일정 학습률 $10^{-5}$, 가중치 감소 $10^{-8}$을 사용한다.
- ImageNet-1K에서 이미지 분류를 위한 Swin Transformer 벤치마킹을 수행한다.
- Results with regular ImageNet-1K training
- 정규 ImageNet-1K 학습 결과, Swin Transformer는 유사한 복잡성을 가진 DeiT 아키텍처를 능가한다.
- Swin-T는 DeiT-S보다 +1.5% 높은 정확도를 달성한다.
- Swin-B도 DeiT-B를 +1.4~1.5% 능가한다.
- Swin Transformer는 RegNet과 EfficientNet 같은 최신 ConvNets보다 약간 더 나은 속도-정확도 trade-off를 달성한다.
- Results with ImageNet-22K pre-training
- ImageNet-22K 사전 학습 결과, Swin-B는 ImageNet-1K에서 처음부터 학습한 것보다 1.8%~1.9% 뛰어나다.
- Swin-B는 86.4%의 top-1 정확도를 달성하여, 비슷한 추론 처리량을 가진 ViT보다 2.4% 높고, Swin-L 모델은 87.3%의 top-1 정확도를 달성하여 Swin-B 모델보다 +0.9% 더 나은 성능을 보인다.
4.2. Object Detection on COCO
- Settings
- COCO 2017에서 객체 탐지 및 인스턴스 분할 실험을 수행하며, 118K 학습, 5K 검증 및 20K 테스트-개발 이미지를 포함한다.
- 네 가지 전형적인 객체 탐지 프레임워크(Cascade Mask R-CNN, ATSS, RepPoints v2, Sparse RCNN)를 사용하여 검증 세트에서 소거 연구를 수행한다.
- 멀티 스케일 학습하기 위해 입력을 리사이징하여 짧은 쪽이 480~800 사이가 되고 긴쪽이 최대 1333이 되도록 한다.
- 시스템 수준 비교를 위해 개선된 HTC(HTC++)를 채택하며, ImageNet-22K 사전 학습 모델을 초기화로 사용한다.
- Swin Transformer는 표준 ConvNets(예: ResNe(X)t) 및 이전 Transformer 네트워크(예: DeiT)와 비교된다.
- Swin Transformer와 ResNe(X)t는 계층적 특징 맵 때문에 모든 프레임워크에 직접 적용 가능하지만, DeiT는 단일 해상도의 특징 맵을 생성하므로 직접 적용할 수 없다.
- Comparison to ResNe(X)t
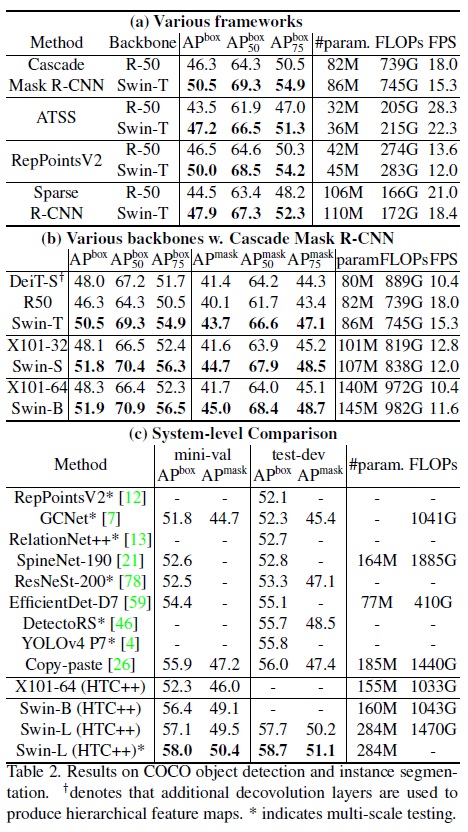
- Table 2(a)는 Swin-T와 ResNet-50의 네 가지 객체 탐지 프레임워크에 대한 결과를 보여준다.
- Swin Transformer는 ResNet-50과 비교하여 일관된 +3.4~4.2 box AP 뛰어나다.
- Table 2(b)는 Cascade Mask RCNN을 사용하여 다른 모델 용량 하에서 Swin Transformer와 ResNe(X)t를 비교한다.
- Swin Transformer는 ResNeXt101-64x4d와 비교하여 +3.6 box AP 및 +3.3 mask AP의 유의미한 성과를 달성한다.
- 개선된 HTC 프레임워크를 사용하여 더 높은 기준선에서 Swin Transformer는 +4.1 box AP 및 +3.1 mask AP의 높은 효과를 보인다.
Table 2 펼치기/접기
- Comparison to DeiT
- Cascade Mask R-CNN 프레임워크를 사용하는 DeiT-S의 성능은 Table 2(b)에 있다.
- DeiT-S와의 비교에서 Swin-T는 비슷한 모델 크기(86M 대 80M)와 더 높은 추론 속도(15.3 FPS 대 10.4 FPS)로 +2.5 box AP 및 +2.3 mask AP 더 높은 성능을 보인다.
- Comparison to previous state-of-the-art
- 우리의 최고 모델은 COCO 테스트-개발에서 58.7 box AP와 51.1 mask AP를 달성하여, 이전 최고 결과를 +2.7 box AP(Copy-paste, 외부 데이터 없음)와 +2.6 mask AP(DetectoRS) 능가한다.
4.3. Semantic Segmentation on ADE20K
- Settings
- ADE20K는 광범위한 150개의 카테고리 범주가 있는 semantic segmentation 데이터셋이다.
- 총 25K 이미지가 있으며, 이 중 20K는 학습, 2K는 검증, 나머지 3K는 테스트로 사용된다.
- 기본 프레임워크로 mmseg의 UperNet을 사용하여 고효율을 달성한다.
- Results
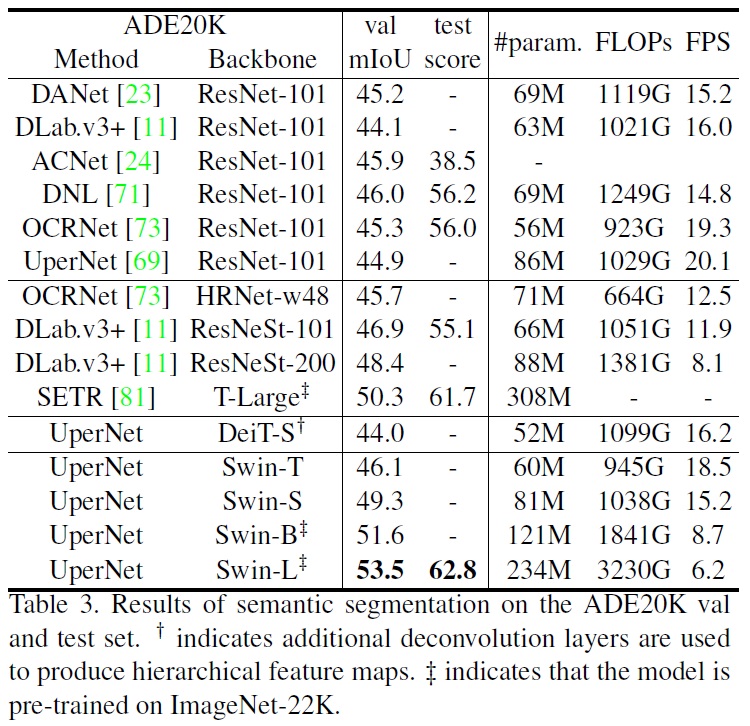
- Table 3에서 다양한 방법/백본 쌍에 대한 mIoU, 모델 크기(#param), FLOPs 및 FPS를 볼 수 있다.
- Swin-S는 비슷한 계산 비용으로 DeiT-S보다 +5.3 mIoU 높은 성능(49.3 대 44.0)을 보인다.
- Swin-S는 ResNet-101보다 +4.4 mIoU, ResNeSt-101보다 +2.4 mIoU 더 높다.
-
ImageNet-22K 사전 학습을 받은 Swin-L 모델은 val 세트에서 53.5 mIoU를 달성하여, 더 큰 모델 크기를 가진 SETR보다 +3.2 mIoU 높은 이전 최고 모델을 초과한다.
4.4. Ablation Study
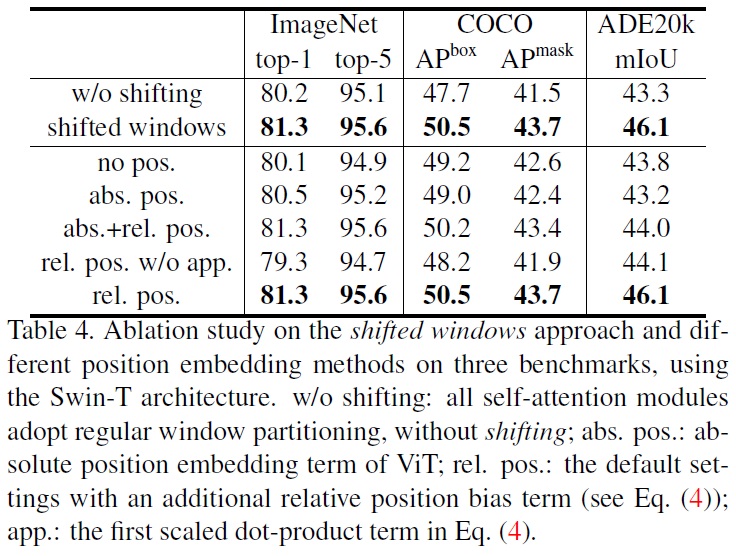
- Shifted windows
- Table 4에서 세가지 작업에 대한 연구 결과를 보여준다.
- 이동된 윈도우 접근 방식은 ImageNet-1K 이미지 분류, COCO 객체 탐지, ADE20K 의미 분할에서 효과적임을 보여준다.
- 이동된 윈도우 분할을 사용한 Swin-T는 단일 윈도우 분할을 기반으로 한 대응 모델보다 더 높은 성능을 보인다.
- Relative position bias
- Table 4에서 다른 위치 임베딩 접근 방식의 비교를 보여준다.
- 상대 위치 편향 사용은 절대 위치 임베딩 포함에 비해 이미지 분류, 객체 탐지, 의미 분할에서 더 나은 성능을 보인다.
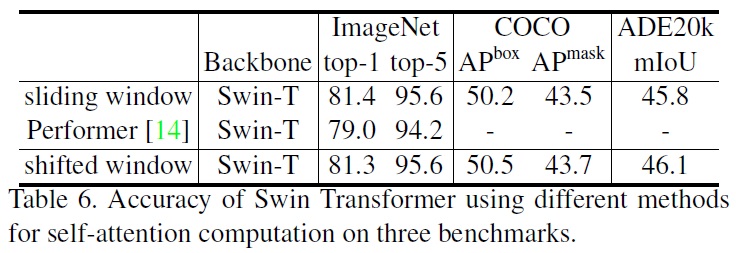
- Different self-attention methods
- 다른 self-attention 계산 방법의 실제 속도를 Table 5에서 비교했으며, 순환 구현은 특히 더 깊은 단계에서 하드웨어 효율적이다.
- Table 6는 Swin-T, Swin-S, Swin-B에 대해 정확도를 비교하여, 시각적 모델링에서 비슷하게 정확함을 보여준다.
-
제안된 이동된 윈도우 기반 self-attention 계산은 Performer와 같은 가장 빠른 Transformer 아키텍처보다 약간 빠르며, ImageNet-1K에서 Swin-T를 사용한 Performer에 비해 +2.3% 더 높은 top-1 정확도를 달성한다.
5. Conclusion
- Swin Transformer는 계층적 특징 표현을 생성하고 입력 이미지 크기에 대해 선형 계산 복잡도를 가지는 새로운 vision Transformer를 제시한다.
- Swin Transformer는 COCO 객체 탐지 및 ADE20K 의미 분할에서 최고의 성능을 달성하여 이전 최고 방법들을 크게 능가한다.
- Swin Transformer의 강력한 성능은 비전 및 언어의 통합 모델링을 장려할 것으로 기대한다.
- Swin Transformer의 핵심 요소인 이동된 윈도우 기반 self-attention은 비전 문제에서 효과적이고 효율적임이 입증되었으며, 자연어 처리에서의 사용을 탐구하는 것을 기대한다.
댓글남기기